
DataFrame in the Pandas library is the name of a two-dimensional data table with a flexible data structure. A DataFrame is organized as a table where each column contains data of the same type (e.g., numbers, strings, dates) and each row represents a separate data set, or record.
A DataFrame is a way of organizing data into a table very similar to the one you might see in Excel. In this table, the rows are individual records or entities, and the columns are the various characteristics or attributes of these item-entities.
For example, if we have a table with information about a construction project, the rows can represent the individual entities-elements of the project and the attributes-columns can represent their categories, parameters, position or coordinates of the BoundingBox elements.
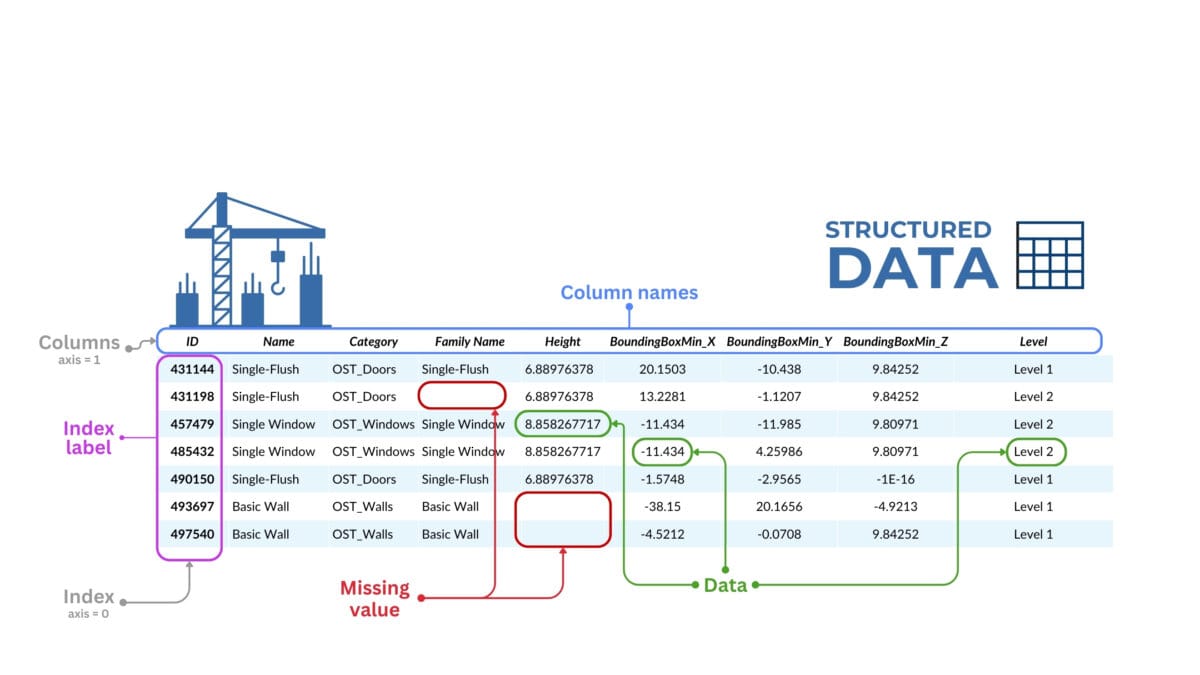
A dataframe of CAD (BIM) data is a two-dimensional table with row and column labels where data can be of different types
Let's list some of the key features and functionality of DataFrame in Pandas:
- Columns: in a DataFrame, data is organized in columns, each with a unique name. Columns-attributes can contain data of different types, similar to columns in databases or columns in tables.
- Rows: in a DataFrame can be indexed with unique values known as a DataFrame index. This index allows to quickly modify and manipulate data on specific rows.
- Index: by default, when a DataFrame is created, Pandas assigns an index from 0 to N-1 to each row (where N is the number of all rows in the DataFrame). However, the index can be modified so that it contains specific labels such as dates or unique identifiers.
- Indexing rows in a DataFrame means assigning each row a unique identifier or label, known as the DataFrame index.
- Data Types: DataFrame supports a variety of data types, including: `int`, `float`, `bool`, `datetime64` and `obect` for text data. Each DataFrame column has its own data type that defines what operations can be performed on its contents.
- Data operations: DataFrame supports a wide range of operations for data processing, including aggregation (`groupby`), merge (`merge` and `join`), concatenation (`concat`), split-apply-combine, and many other methods for manipulating and transforming data.
- Size Manipulation: DataFrame allows to add and remove columns and rows, making it a dynamic structure that can be modified according to data analysis needs.
- Data Visualization: using built-in visualization techniques or interfacing with popular data visualization libraries such as Matplotlib or Seaborn, DataFrame can be easily converted to graphs and charts to present data graphically.
- Data input and output: Pandas provides functions to read import and export data to various file formats such as CSV, Excel, JSON, HTML and SQL, making DataFrame a central hub for data collection and distribution.
These are just the main features and capabilities of DataFrame, but they already make it an indispensable tool for importing, organizing, analyzing, validating, and processing and exporting multi-format and multi-structured data. We will talk more about types of other formats Parquet, Apache orc, JSON, Father, HDF5 and data warehouses in the chapter "Modern data technologies in the construction industry".
The Pandas library and the DataFrame format, due to their popularity and ease of use, have become the primary tools for data processing and automation in the ChatGPT model (in 2023-2024). ChatGPT considers using Pandas and Python often the default when handling queries related to data validation, analysis, and processing.



















































