

Pandas occupies a special place in the world of data analysis and automation. It is one of the most popular and widely used libraries of the Python programming language(“Python Packages Download Stats,” 2024), designed to work with structured data.
A library is like a set of ready-made tools: functions, modules, classes. Just as on a construction site you don’t need to invent a hammer or a level every time, so in programming libraries allow you to quickly solve problems without reinventing basic functions and solutions.
Pandas is an open source Python library , providing high-performance and intuitive data structures, in particular DataFrame, a universal format for working with tables. Pandas is a Swiss knife for data-driven analysts, engineers, and developers.
Python is a high-level programming language with a simple syntax that is actively used in analytics, automation, machine learning, and web development. Its popularity is due to its code readability, cross-platform nature, and rich ecosystem of libraries. To date, more than 137,000 open source packages have been created for Python (Interview Bit, “Top 10 Python Libraries,” 2023), and this number continues to grow almost daily. Each such library is a kind of repository of ready-made functions: from simple mathematical operations to complex tools for image processing, big data analysis, neural networks, and integration with external services.
In other words, imagine that you have free and open access to hundreds of thousands of out-of-the-box software solutions – libraries and tools that you can directly embed into your business processes. It’s like a huge catalog of applications for automation, analysis, visualization, integration, and more – and it’s all available right after you install Python.
Pandas is one of the most popular packages in the Python ecosystem. In 2022, the average number of downloads of the Pandas library reached 4 million per day (Fig. 3.4-3), whereas by early 2025, this Fig. has increased to 12 million downloads per day, reflecting its growing popularity and widespread use in data analytics and LLM chat(“Python Packages Download Stats,” 2024)]

The query language in the Pandas library is similar in functionality to the SQL query language, which we discussed in the chapter “Relational Databases and SQL Query Language”.
In the world of analytics and structured data management, Pandas stands out for its simplicity, speed and power, providing users with a wide range of tools to effectively analyze and process information.
Both tools – SQL and Pandas – provide powerful data manipulation capabilities, especially when compared to traditional Excel. They support operations such as sampling, filtering (Fig. 3.4-4), with the only difference being that SQL is optimized for working with relational databases, while Pandas processes data in RAM, which allows it to run on any computer, without the need to create databases and deploy a separate infrastructure.

Pandas is often preferred for scientific research, process automation, pipeline creation (including ETL) and data manipulation in Python, while SQL is a database management standard and is often used in enterprise environments to handle large amounts of data.
The Pandas library of the Python programming language allows you to perform not only basic operations such as reading and writing tables, but also more complex tasks, including merging data, grouping data, and performing complex analytical calculations.
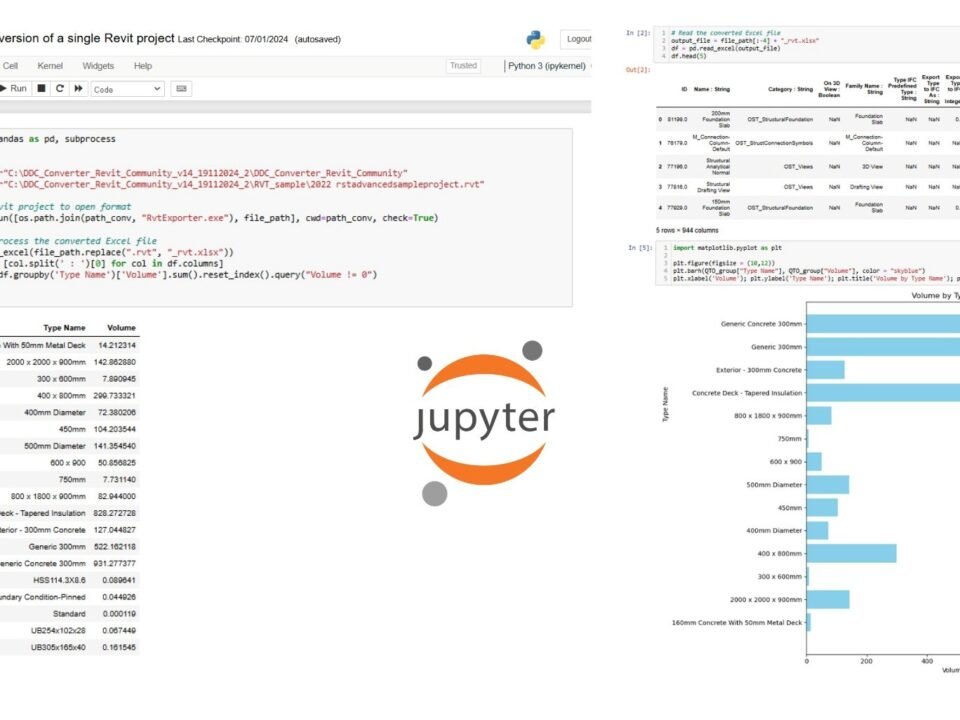
Today, the Pandas library is used not only in academic research and business analytics, but also in conjunction with LLM -models. For example, Meta® division (Facebook™), when publishing a new open source model LlaMa 3.1 in 2024, paid special attention to working with structured data, making one of the key and first cases in its release the processing of structured dataframes (Fig. 3.4-5) in CSV format and integration with Pandas library directly in chat.

Pandas is an essential tool for millions of data scientists processing and preparing data for generative AI. Accelerating Pandas with zero code changes will be a huge step forward. Data scientists will be able to process data in minutes instead of hours and get orders of magnitude more data to train generative AI models (“NVIDIA and HP Supercharge Data Science and Generative AI on Workstations,” 7 Mar. 2025).
– Jensen Huang, founder and CEO of NVIDIA
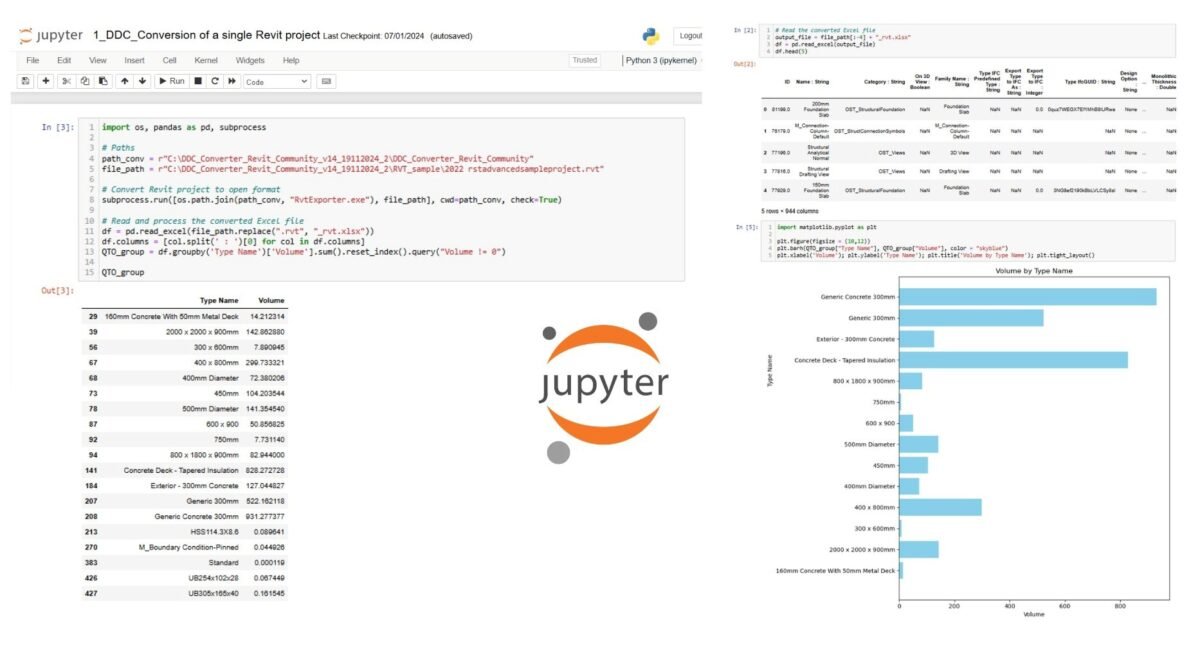
Using Pandas, you can manage and analyze datasets far beyond the capabilities of Excel. While Excel is typically capable of handling up to 1 million rows of data, Pandas can easily handle datasets (Fig. 9.1-2, Fig. 9.1-10) containing tens of millions of rows (Р. Orac, “How to process a DataFrame with millions of rows in seconds,” 2024). This capability allows users to perform sophisticated data analysis and visualization on large datasets, providing deep insights and facilitating data-driven decision making. In addition, Pandas has strong community support (Ç. Uslu, “What is Kaggle?,” 2024): hundreds of millions of developers and analysts worldwide (Kaggle.com, Google Collab, Microsoft® Azure™ Notebooks, Amazon SageMaker) use it online or offline every day, providing a large number of out-of-the-box solutions for any business problem.
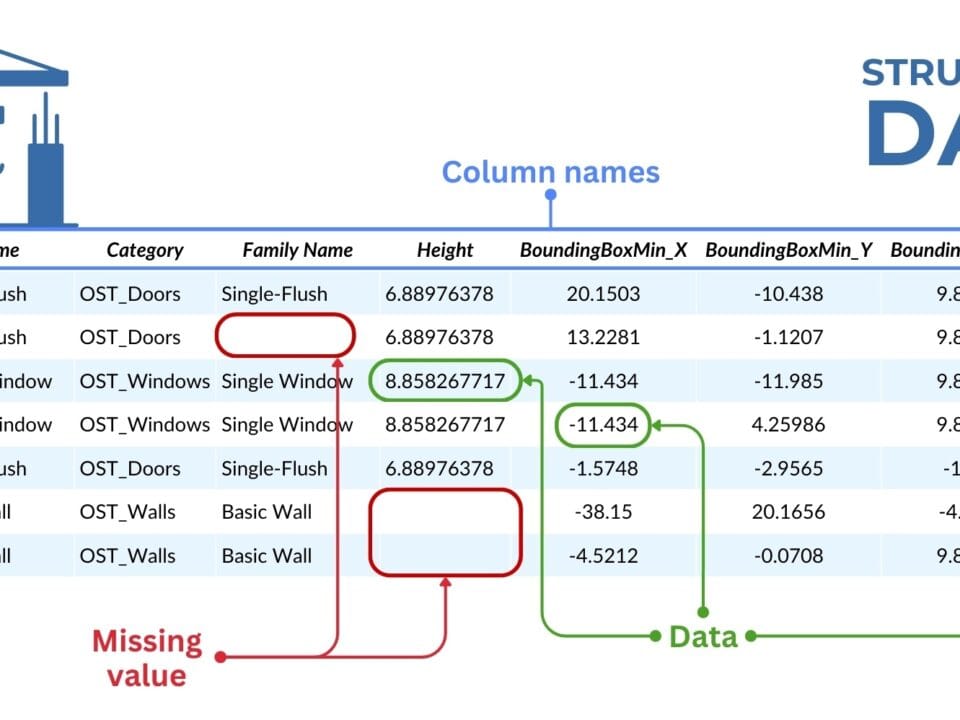
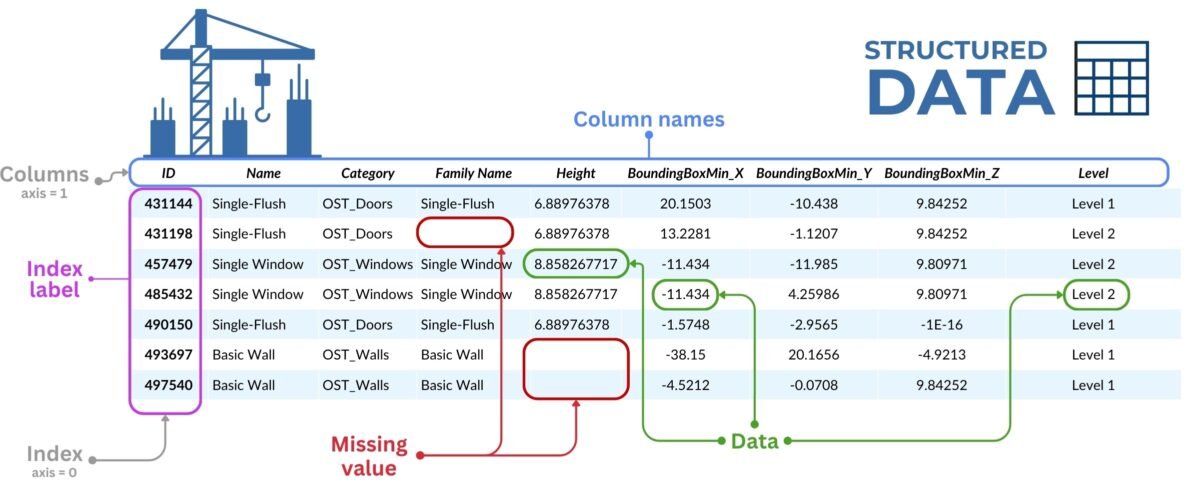
At the heart of most Python analytic processes is a structured form of data called DataFrame, provided by the Pandas library. It is a powerful and flexible tool for organizing, analyzing, and visualizing tabular data.




















































{kind=link}
{kind=link}