

Up to 80% of data created in companies is in unstructured or semi-structured formats (“Structured and unstructured data: What’s the Difference?,” 2024) – text, documents, letters, PDF -files, conversations. Such data (Fig. 4.4-1) is difficult to analyze, verify, transfer between systems and use in automation.
To ensure manageability, transparency, and automatic validation, it is necessary to translate textual and semi-structured requirements into well-defined, structured formats. The structuring process concerns not only the data (which we discussed in detail in the first chapters of this part of the book), but also the requirements themselves, which project participants usually formulate in free text form throughout the project lifecycle, often without thinking that these processes can be automated.
Just as we have already converted data from an unstructured textual form to a structured form, in the requirements workflow we will convert textual requirements to a structured “logical and physical layer” format.
Within the example of adding a window (Fig. 4.4-1), the next step is to describe the data requirements in tabular form. We will structure the information for each system used by the project participants by specifying key attributes and their boundary values
Consider, for example, one such system (Fig. 4.4-5) – Construction Quality Management System (CQMS), which is used by the quality control engineer on the client’s side. With its help he checks whether a new element of the project – in this case “new window” – complies with the established standards and requirements.

As an example, consider some important requirements for attributes of entities of type “window systems” in CQMS -system (Fig. 4.4-6): energy efficiency, acoustic performance and warranty period. Each category includes certain standards and specifications that need to be considered when designing and installing window systems.

The data requirements that a QA engineer specifies in a table have, for example, the following boundary values:
- The energy efficiency class of windows ranges from “A++”, denoting the highest efficiency, to “B”, considered the minimum acceptable level, and these classes are represented by a list of acceptable values [“A++”, “A+”, “A”, “A”, “A”, “B”].
- The acoustic insulation of windows, measured in decibels and indicating their ability to reduce street noise, is defined by the regular expression \d{2}dB.
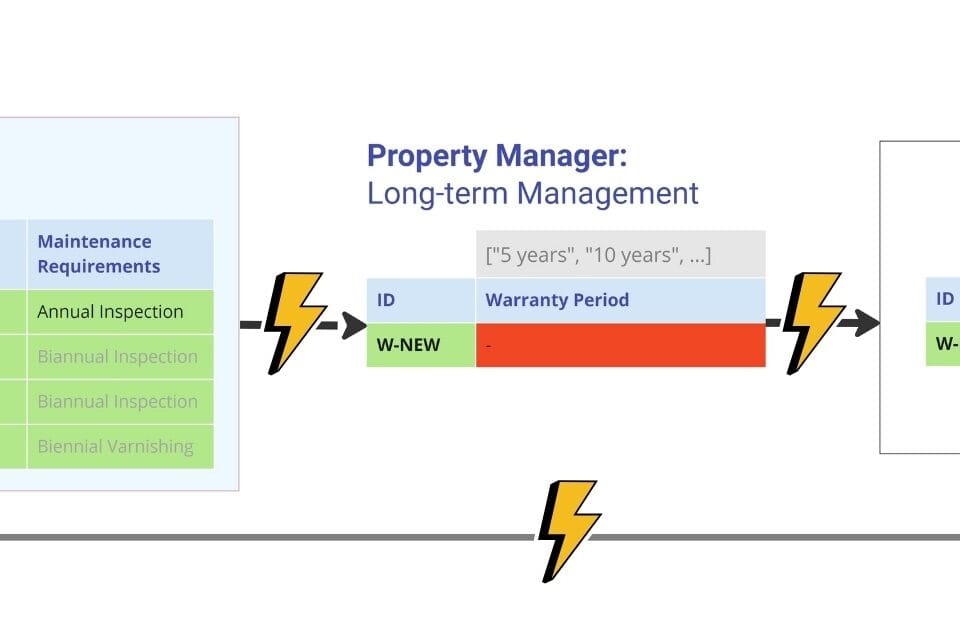
- The “Warranty Period” attribute for the Window Type entity starts at five years, setting this period as the minimum allowed when selecting a product; warranty period values such as [“5 years”, “10 years”, etc.] or the logical condition “>5 (years)” are also specified.
According to the collected requirements, within the established attributes, new window category or class elements with grades below “B” such as “C” or “D” will not pass the energy efficiency test. Acoustical insulation of windows in data or documents to the QA Engineer shall be labeled with a two-digit number followed by the postfix “dB”, such as “35 dB” or “40 dB”, and values outside this format such as “9 D B” or “100 decibels” will not be accepted (as they will not pass the pattern for RegEx strings). The warranty period must begin with a minimum of “5 years” and windows with shorter warranty periods such as “3 years” or “4 years” will not meet the requirements that the Quality Engineer has described in the table format.
To check such attribute-parameter values against boundary values from requirements in the validation process, we use either a list of allowed values ([“A”, “B”, “C”]), dictionaries ([“A”: “H1”, “H2”; “B”: W1″, “W2”]), logical operations (e.g., “>”, “<“, “<=”, “>=” “==”) for numeric values) and regular expressions (for string and text values such as in the “Acoustic Performance” attribute). Regular expressions are an extremely important tool when working with string values.
Regular expressions (RegEx) are used in programming languages, including Python (Re library), to find and modify strings. Regex is like a detective in the string world, able to identify text patterns in text with precision.
In regular expressions, letters are described directly using the corresponding alphabet characters, while numbers can be represented using the special character \d, which corresponds to any digit from 0 to 9. Square brackets are used to indicate a range of letters or digits, e.g., [a-z] for any lowercase letter of the Latin alphabet or [0-9], which is equivalent to \d. For non-numeric and non-letter characters, \D and \W are used, respectively.
Popular RegEx use cases (Fig. 4.4-7):
- Verifying email address: to check if a string is a valid email address, you can use the template “^ [a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$”.
- Date Extraction: “\b\d{2}\d{2}\d{2}\d{2}\d{2}\d{2}\d{2}\d{2}\d{2}\.\d{4}\b” template can be used to extract date from text in DD.MM.YYYYYY format.
- Verifying phone numbers: to verify phone numbers in the format +49(000)000-0000, the pattern will look like “\+\d{2}\(\d{3}\)\d{3}-\d{4}”.
By translating the requirements of a QA engineer into the format of attributes and their boundary values (Fig. 4.4-6), we have transformed them from their original text format (conversations, letters, and regulatory documents) into an organized and structured table, thus making it possible to automatically check and analyze any incoming data (e.g., new elements of the Window category). The presence of requirements allows for the automatic discarding of data that has not been checked, while the checked data is automatically transferred to the systems for further processing.

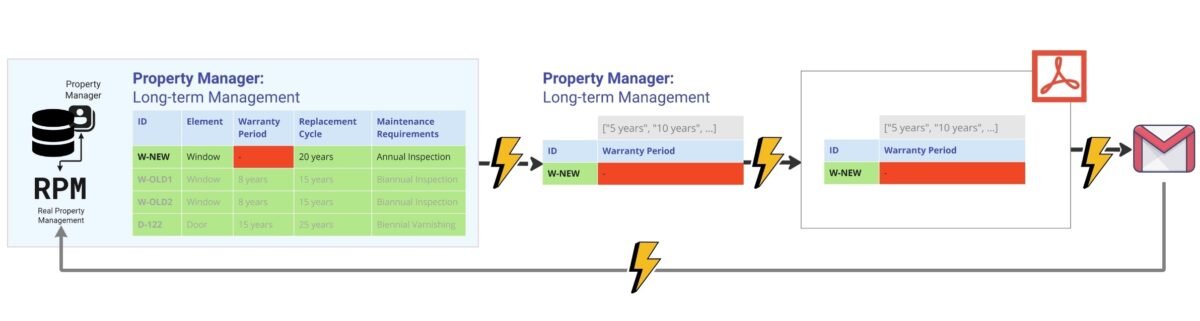
Now, moving from the conceptual to the logical level of working with requirements, we will convert all requirements of all specialists in our process of installing a new window (Fig. 4.4-4) into an organized list in attribute format and add these lists with the necessary attributes to our flowchart for each specialist (Fig. 4.4-8).

By adding all attributes to one common process table, we transform the information previously presented as text and dialogue at the conceptual level (Fig. 4.4-1) into the structured and systematized form of physical-level tables (Fig. 4.4-9).

Now the data requirements need to be communicated to the specialists creating information for specific systems. For example, if you are working in a CAD database, before you start modeling elements, you should collect all the necessary parameters based on the end use scenarios of this data. This usually starts with the operational phase, followed by the construction site, the logistics department, the estimating department, the structural calculations department, and so on. Only after you have taken into account the requirements of all these links can you start creating data – based on the parameters collected. This will allow you to automate the verification and transfer of data along the chain.
When new data meets the requirements, it is automatically integrated into the company’s data ecosystem, going directly to the users and systems for which it was intended. Verification of data against attributes and their values ensures that the information meets the required quality standards and is ready to be applied to company scenarios.
The data requirements have been defined and now, before verification can begin, the data to be verified must be created, obtained or collected, or the current state of information in databases must be recorded to be used in the verification process.




















































{kind=link}