
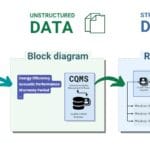

Before starting validation, it is important to make sure that the data are available in a form suitable for the validation process. This means not just having the information available, but preparing it: the data must be collected and transformed from unstructured, loosely structured, textual, and geometric formats into a structured form. This process is described in detail in the previous chapters, where methods for transforming different types of data were discussed. As a result of all transformations, the incoming data takes the form of open structured tables (Fig. 4.1-2, Fig. 4.1-9, Fig. 4.1-13).
With the requirements and structured tables with the necessary parameters and boundary values (Fig. 4.4-9), we can start validating the data – either as a single automated process (Pipeline) or as a step-by-step validation of each incoming document.
In order to start the check, it is required either to receive a new file as input or to fix the current state of the data – to create a snapshot or export current and incoming data, or to set up a connection to an external or internal database. In the example under consideration, such a snapshot is created by automatically converting CAD data from into a structured format recorded at, say, 23:00:00 on Friday, March 29, 2024, after all designers have gone home.

Thanks to the reverse engineering tools discussed in the chapter “Translating CAD data (BIM) into a structured form”, this information from different CAD (BIM) tools and editors can be organized into separate tables (Fig. 4.4-11) or combined into one common table connecting different sections of the project (Fig. 9.1-10).
Such table – database displays unique identifiers of windows and doors (ID attribute), type names (TypeName), dimensions (Width, Length), materials (Material), as well as indicators of energy and acoustic efficiency, and other characteristics. Such a table filled in CAD program (BIM) is collected by a design engineer from various departments and documents, forming an information model of the project.

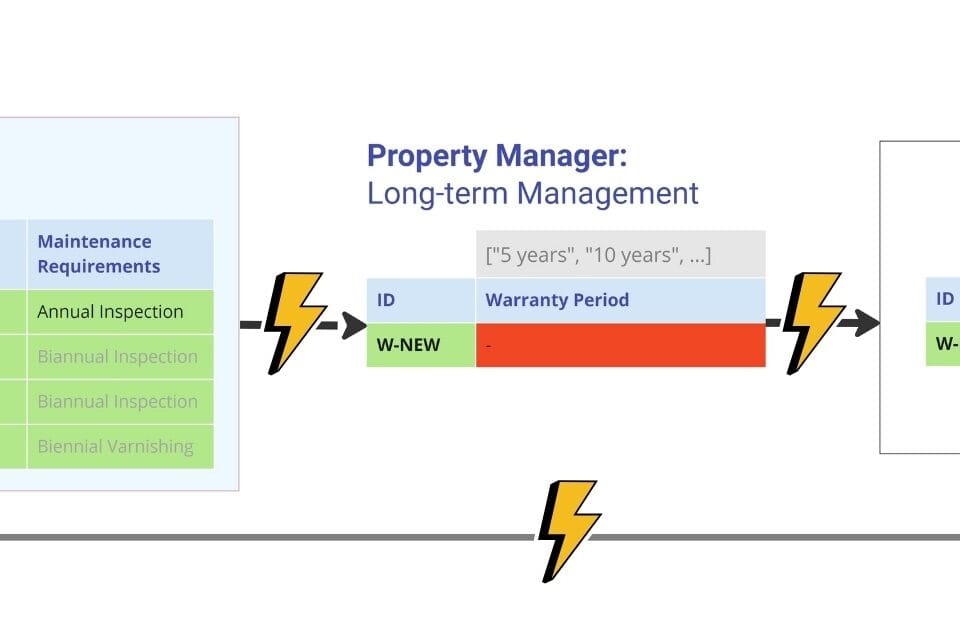
Real CAD (BIM) projects include tens or hundreds of thousands of elements (Fig. 9.1-10). Elements within CAD formats are automatically categorized by type and category, from windows and doors to slabs, floors and walls. Unique identifiers (e.g., native ID, which is set automatically by the CAD solution) or type attributes (Type Name, Type, Family) allow the same object to be tracked in different systems. For example, a new window on the north wall of a building can be uniquely identified through a single ID “W-NEW” in all relevant systems of the organization.
While entity names and identifiers should be consistent across all systems, the set of attributes and values associated with these entities can vary significantly depending on the context of use. Architects, structural engineers, construction, logistics, and real estate operations professionals perceive the same elements in different ways. Each of them relies on their own classifiers, standards and objectives: some consider the window from a purely aesthetic point of view, evaluating its shape and proportions, while others consider it from an engineering or operational point of view, analyzing thermal conductivity, installation method, weight or maintenance requirements. Therefore, when modeling data and describing elements, it is important to take into account the versatility of their use and ensure consistency of data while taking into account industry specifics.
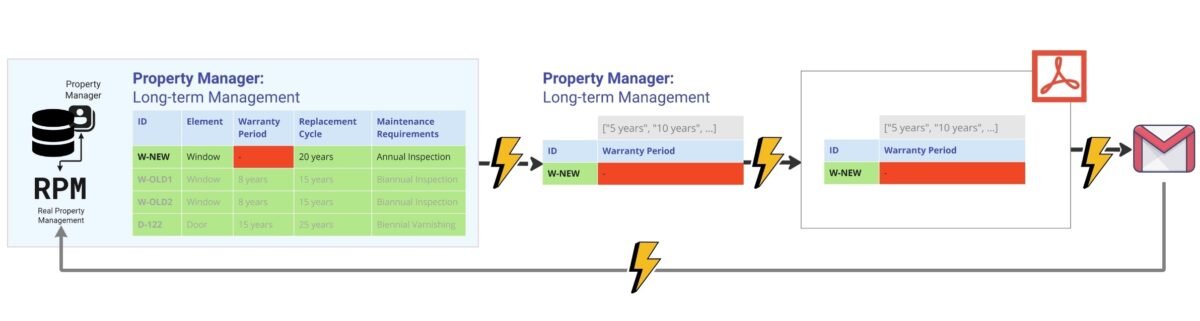
For each role in the company’s processes there are specialized databases with their own user interface – from design and calculations to logistics, installation and building operation (Fig. 4.4-12). Each such system is managed by a professional team of specialists through a special user interface or through database queries, where the sum of all decisions made on the entered values at the end of the chain is followed by the system manager or department manager, who is responsible for the legal validity and quality of the entered data before their counterparties serving other systems.

Once we have organized the collection of structured requirements and data at the logical and physical level, it remains for us to set up a process to automatically validate the data from different incoming documents and different systems against the previously collected requirements.




















































{kind=link}