

All new data entering the system – be it documents, tables or database entries from the client, architect, engineer, foreman, logistician or property manager – must be validated against the requirements formulated earlier (Fig. 4.4-9). The validation process is critical: any errors in the data can lead to incorrect calculations, schedule delays, and even financial losses. To minimize such risks, it is necessary to organize a systematic and repeatable, iterative data validation procedure.
To validate new data entering the system – unstructured, textual or geometric – it must be converted into a loosely structured or structured format. The validation process must then check the data against the full list of required attributes and their allowed values.
Converting different types of data: text, images, PDF -documents and mixed CAD (BIM) data into a structured form was discussed in detail in the chapter “Converting data into a structured form”.
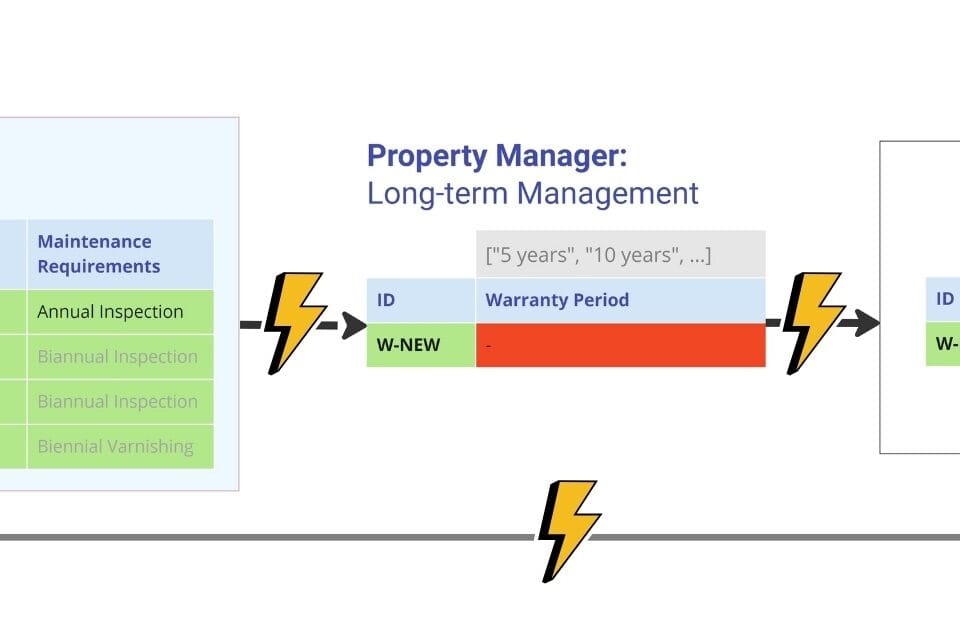
An example is a table obtained from CAD (BIM) of a project (Fig. 4.4-11). It includes semi-structured geometric data and structured attribute information on project entities (Fig. 3.1-14) – for example an element from the class “Windows”.
To perform the validation, we compare the attribute values (Fig. 4.4-11) with the reference boundary values that were defined by experts in the form of a requirement (Fig. 4.4-9). The final comparison table (Fig. 4.4-13) will allow us to understand which values are acceptable and which ones need to be corrected before the data can be used outside of CAD applications (BIM).

Implementing a similar solution using the Pandas library, which we described earlier in the chapter “Pandas: An Indispensable Tool for Data Analysis”, we will validate data from a tabular file extracted from a CAD file (BIM) (RVT, IFC, DWG, NWS, DGN) (Fig. 4.4-11) using requirements from another tabular requirements file (Fig. 4.4-9).
To get the code, we need to describe in the prompt for LLM that we need to load the data from the file raw_data.xlsx (a complete set of data from the CAD database (BIM)), check them and save the result in a new file checked_data.xlsx (Fig. 4.4-13).
- Let’s get the code using LLM without mentioning the Pandas library:
Write code to check the table from the raw_data.xlsx file and validate them using the following validation rules: the values of the ‘Width’ and ‘Length’ columns are greater than zero, ‘Energy Rating’ is included in the [‘A++’, ‘A+’, ‘A’, ‘B’] list, and ‘Acoustic Performance’ as a variable that we’ll specify later – with the final validation column added, and save the final table to a new Excel file checked_data.xlsx ⏎

The code generated by the LLM language model, can be used in any popular IDE or online tool: PyCharm, Visual Studio Code (VS Code), Jupyter Notebook, Spyder, Atom, Sublime Text, Eclipse with PyDev plugin, Thonny, Wing IDE, IntelliJ IDEA with Python plugin, JupyterLab or popular online tools Kaggle.com, Google Collab, Microsoft Azure Notebooks, Amazon SageMaker.
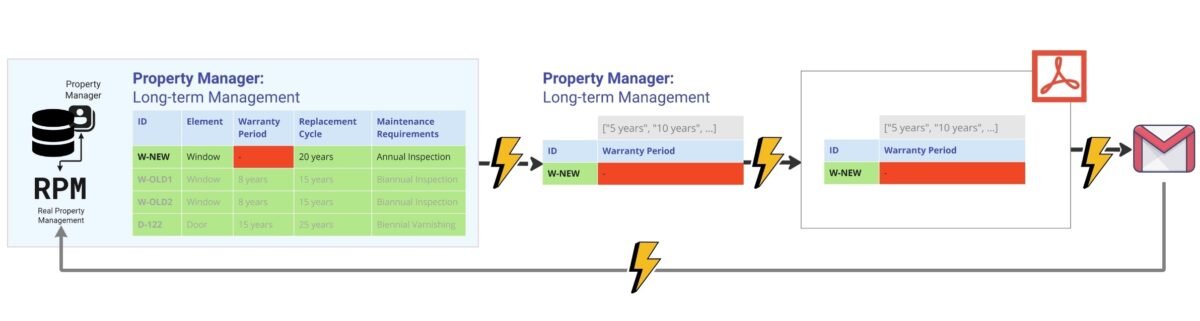
Execution of the code (Fig. 4.4-14) will show that the “entity elements” W-OLD1, W-OLD2, D-122 (and other elements) from the CAD database (BIM) meet the attribute requirements: width and length are greater than zero, and the energy efficiency class is one of the list values ‘A++’, ‘A’, ‘B’, ‘C’ (Fig. 4.4-15).
The W-NEW element we need and recently added, which is responsible for the new element class “Window” on the north side, is not compliant (attribute “Requrments Met”) because its length is zero (a value of “0.0” is considered unacceptable by our ‘Width’>0 rule) and it does not specify an energy efficiency class.

Similarly, we check the consistency of all project elements (entities) and required attributes for each of the systems, tables or databases in all the data we receive from different specialists (Fig. 4.4-1) during the process of adding a window to the project.
In the final table it is convenient to highlight the results of the check by color for visualization: attributes that successfully passed the check are marked in green, yellow – values with non-critical deviations, and red – critical inconsistencies (Fig. 4.4-16).
As a result of the validation (Fig. 4.4-16), we get a list of trusted and validated elements with their IDs that have been verified to meet attribute requirements. Validated elements provide assurance that these elements meet the stated standards and specifications for all systems involved in the process of adding elements of the Window class or any other class (we will talk more about automating data validation and creating an automated ETL process in the chapter “Automating ETL and Data Validation”).

Entities that have been successfully validated usually do not require much attention. They move on to the next stages of processing and integration into other systems without obstacles. In contrast to “quality” items, it is the items that fail validation that are of greatest interest. Information about such deviations is critical: it should be communicated not only in the form of tabular reports, but also using various visualization tools. Graphical representation of inspection results helps to quickly assess the overall state of data quality, identify problem areas and promptly take measures to correct or refine parameters.




















































{kind=link}