
Modern CAD (BIM) platforms have significantly transformed the approach to design and construction information management. While previously these tools were mainly used to create drawings and 3D models, today they serve as full-fledged repositories of design data. Under the Single Source of Truth concept, the parametric model is increasingly becoming the main and often the only source of project information, ensuring its integrity and relevance throughout the entire lifecycle of an object.
The key difference between CAD – (BIM -) platforms and other construction data management systems is the need to use specialized tools and APIs to access the information (the only source of truth). These databases are not universal in the traditional sense: instead of an open structure and flexible integration, they are a closed environment, hardwired to a specific platform and format.
Despite the complexity of working with CAD -data there is a more important question that goes beyond the technical realization: what are CAD databases (BIM) really? To answer this question, it is necessary to go beyond the usual acronyms and concepts imposed by software developers. Instead, it is worth focusing on the essence of working with project information: data and its processing.
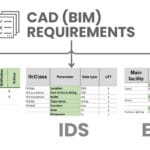
The business process in construction begins not with work in CAD – or BIM – tools, but with the formation of project requirements and data modeling. First, the task parameters are defined: the list of entities, their initial characteristics and boundary values that need to be considered when solving a particular task. Only after that models and elements are created in CAD (BIM) systems on the basis of the specified parameters
The process that precedes the creation of information in CAD – (BIM-) databases is completely the same as the data modeling process that was discussed in detail in the fourth part of the book and the chapter “Data Modeling: conceptual, logical and physical model” (Fig. 4.3-1).
Just as in data modeling we create requirements for the data we later want to process in the database, for CAD databases, managers create design requirements in the form of several table columns or lists of key-value pairs (Fig. 6.4-1, steps 1-2). And only on the basis of these initial parameters using the API automatically or manually, the designer creates (or rather refines) objects in CAD- (BIM) databases (steps 3-4), after which they are checked again for compliance with the initial requirements (steps 5-6). This process – definition→ creation→ validation→ adjustment (steps 2-6) – is repeated iteratively until the data quality, just as in data modeling, reaches the desired level for the target system – documents, tables or dashboards (step 7).
 the path to analytics and open formats")
If we consider CAD (BIM) as a mechanism for parameter transfer in the form of a set of key-value pairs generated on the basis of requirements defined outside the design environment (Fig. 6.4-1, steps 1-2), the focus of the discussion shifts from specific software solutions and their limitations to more fundamental aspects – data structure, data models and data requirements. In essence, we are talking about parameter saturation of the database and the classical data modeling process (steps 2-3 and 5-6). The only difference is that due to the closed nature of CAD-databases and the peculiarities of the formats used, this process is accompanied by the use of specialized BIM-tools. The question arises: what is the uniqueness of BIM, if there are no similar approaches in other industries?
For the last 20 years, BIM has been positioned as more than just a single data source. The CAD -BIM marketing bundle is often sold as a parametric tool with an inherently integrated database (ADSK, “Whitepaper BIM,” 2002. [On the Internet]. Available: https://web.archive.org/web/20060512180953/http:/images.autodesk.com/apac_sapac_main/files/4525081_BIM_WP_Rev5.pdf#expand. [Date of address: 15 March 2025]), capable of automating the processes of design, modeling and life cycle management of construction objects. However, in reality, BIM has become more a tool to keep users on the vendors’ platform than a convenient method of data and process management.
As a result, CAD- (BIM-) data is isolated within their platforms, hiding project information behind proprietary APIs and geometry kernels. This has deprived users of the ability to independently access databases and extract, analyze, automate, and transfer data to other systems, bypassing vendor ecosystems.
 the path to analytics and open formats")
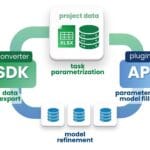
Companies that work with modern CAD tools should use the same approach to working with data that all CAD vendors themselves without exception use in practice: data transformation using SDK – reverse engineering tools,which CAD vendors have been fighting against since 1995 (А. Boiko, “The struggle for open data in the construction industry. The history of AUTOLISP, intelliCAD, openDWG, ODA and openCASCADE,” 15 05 2024). Having full access to the CAD database and using reverse engineering tools, we can obtain (А. Boiko, “ENG BIM Cluster 2024 | The Battle for Data and Application of LLM and ChatGPT in the Construction,” August 7, 2024)a flat set of entities with attributes and export them to any convenient open format (Fig. 6.4-2), including both geometry and parameters of design elements. This approach fundamentally changes the paradigm of working with information – from file-oriented to data-centered architecture:
- Data formats such as RVT, IFC, PLN, DB1, CP2, CPIXML, USD, SQLite, XLSX, PARQUET and others contain identical information about elements of the same project. This means that knowledge of a particular format and its schema should not be a barrier to working with the data itself.
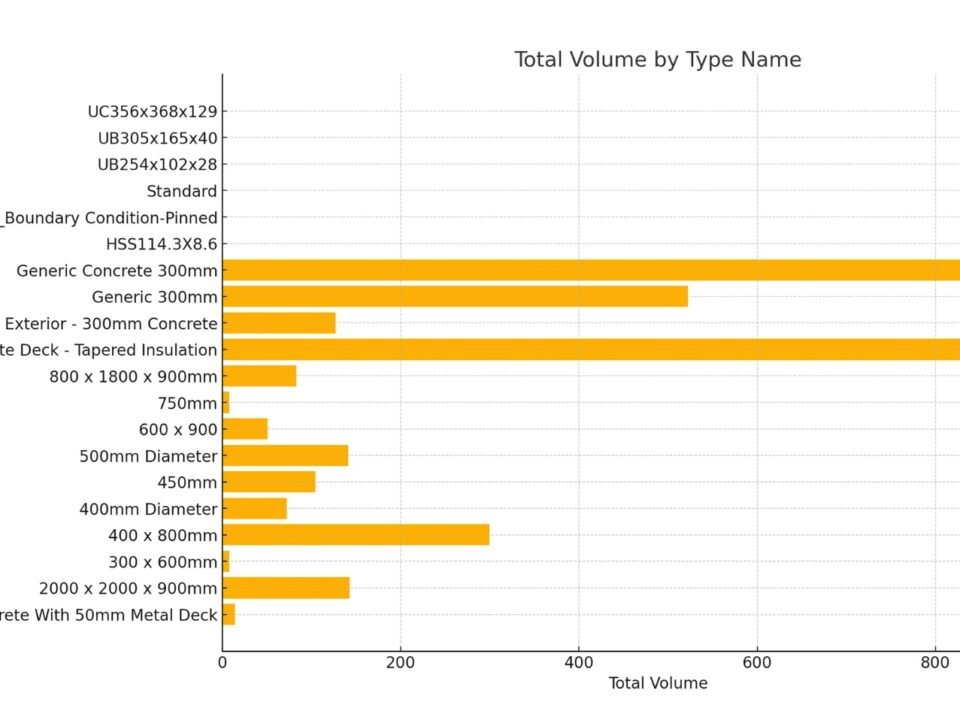
- Data from any formats can be combined into a single open structured and granular structure (Fig. 9.1-10) containing the MESH triangular geometry and the properties of all object entities, without the constraints of geometric kernels.
- Data analytics strives for universality: using open data, you can work with project data regardless of the format used.
- Minimization as well as dependency on APIs and vendor plugins: working with data no longer depends on API skills.
When and CAD -data requirements are transformed into analytics-friendly structured representation formats – developers are no longer dependent on specific data schemas and closed ecosystems.





















































{kind=link}
{kind=link}