

At the Load stage, the results were generated in the form of tables, graphs and final PDF reports prepared in accordance with the established requirements. Further it is possible to export this data into machine-readable formats (e.g. CSV), which is necessary for integration with external systems such as ERP, CAFM, CPM, BI platforms and other corporate or industry solutions. In addition to CSV, uploads can be made to XLSX, JSON, XML or directly to databases that support automatic information exchange.
- To generate the appropriate code to automate the Load step, simply query the LLM -interface, for example: ChatGPT, LlaMa, Mistral DeepSeek, Grok, Claude or QWEN:
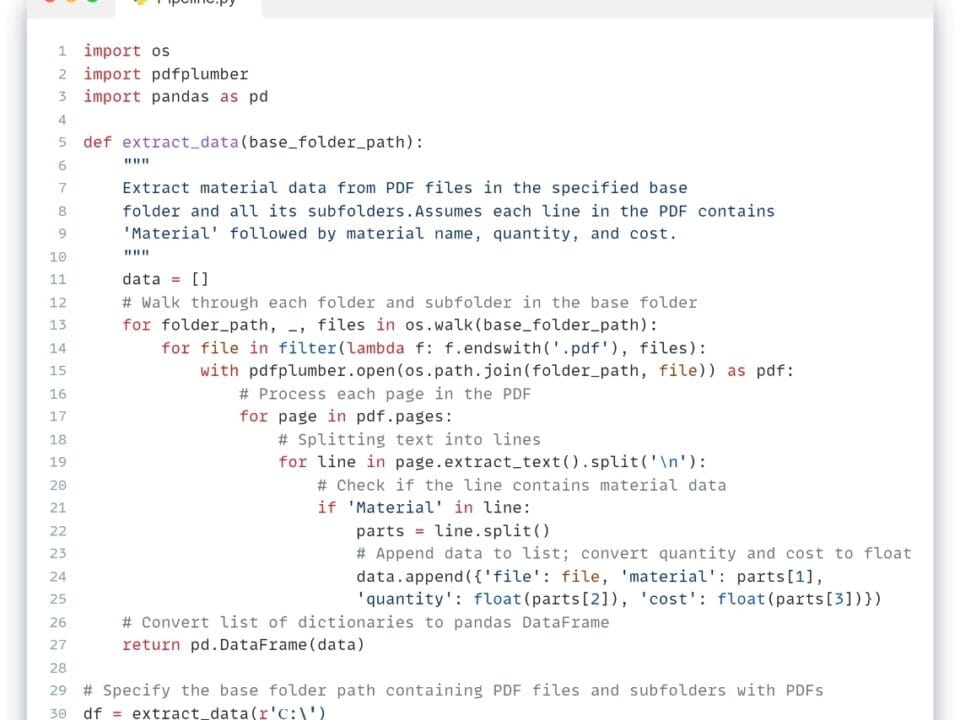
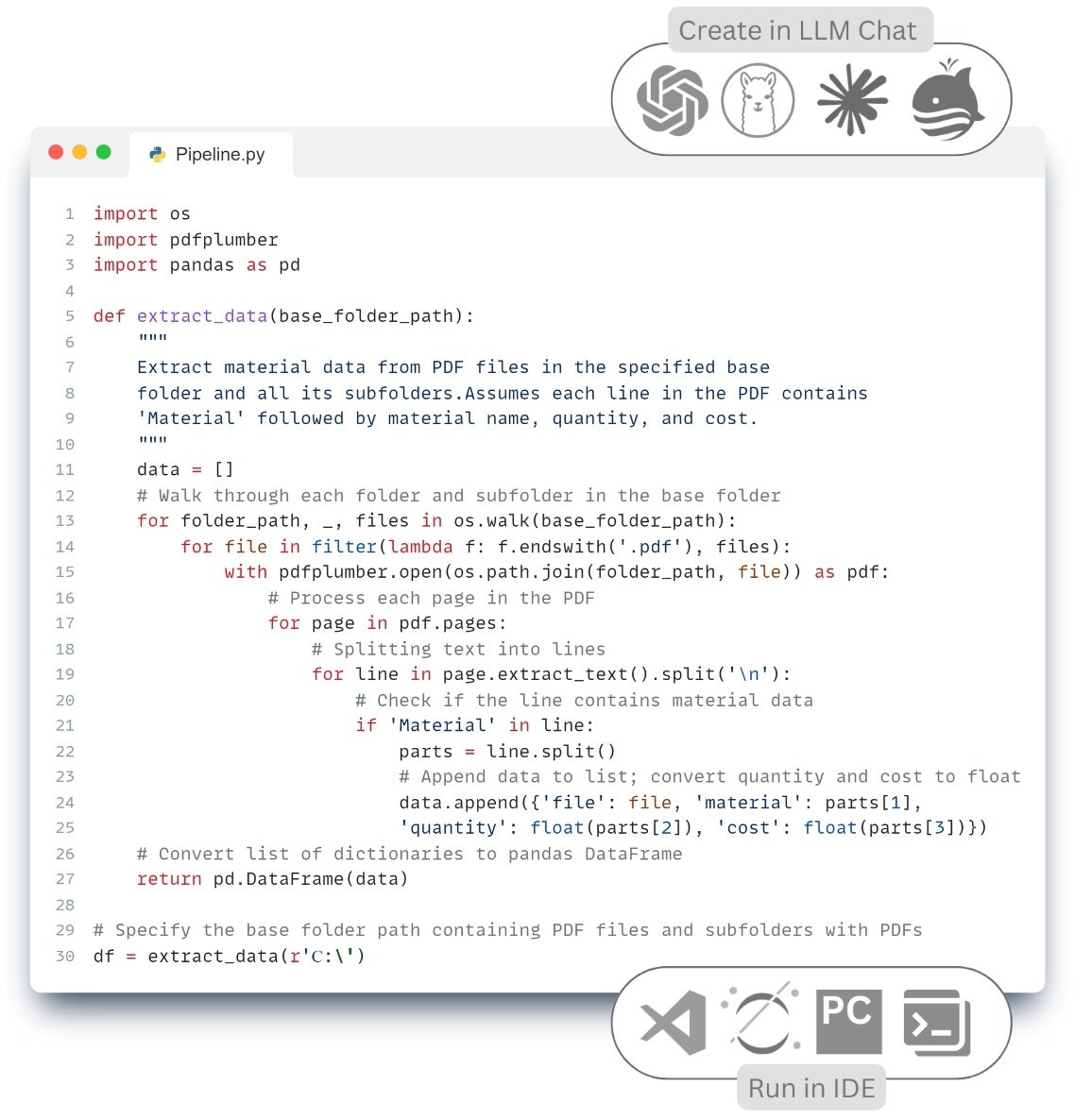
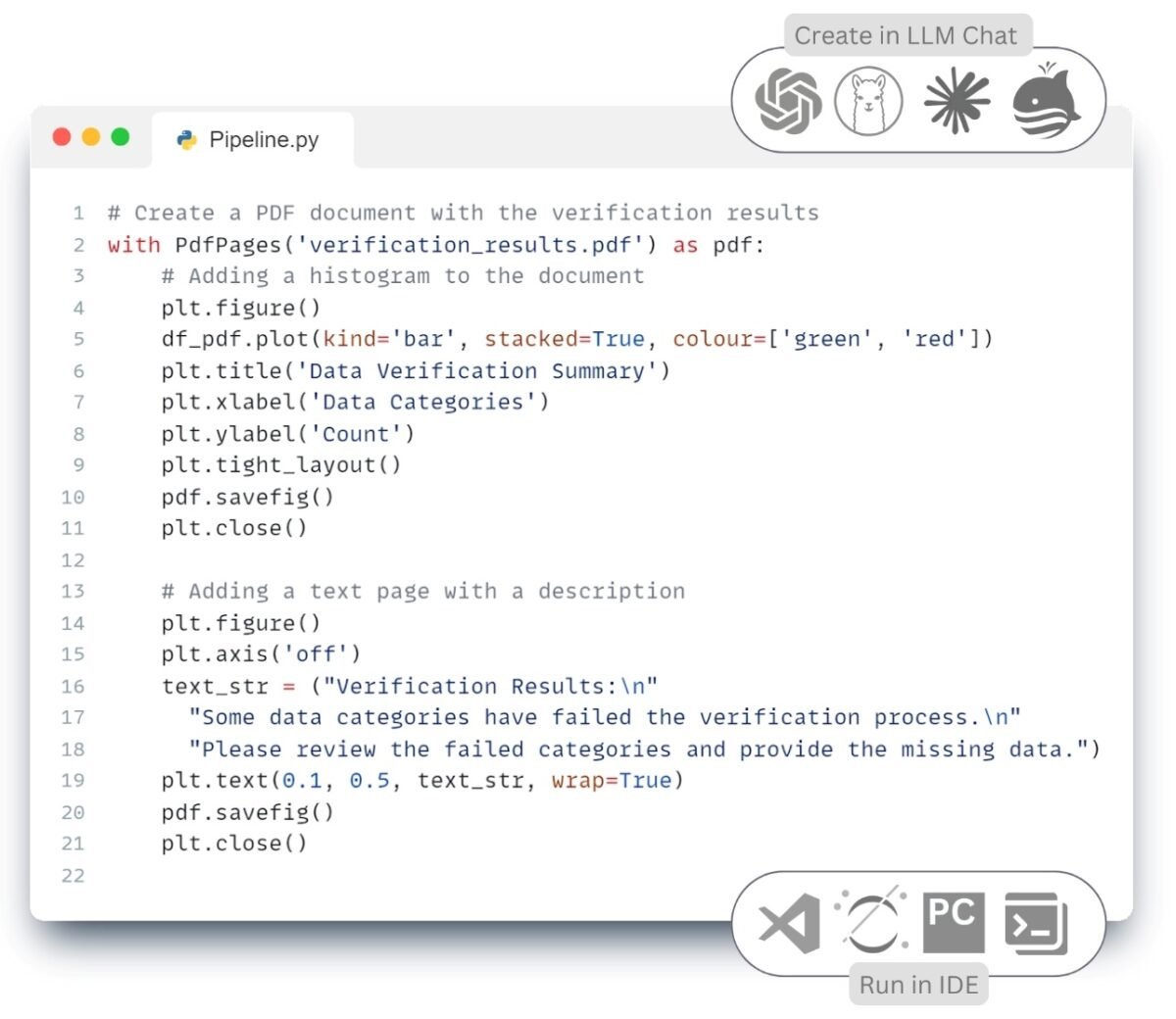
Write code to generate a report of data validation results in DataFrame, where columns prefixed with ‘verified_’ are counted, renamed to ‘Passed’ and ‘Failed’, missing values are replaced with 0, and then only those rows that pass all validations are exported to a CSV -file.
- LLM’s response:

In the given code (Fig. 7.2-17) the final stage of ETL -process – Load – is realized, during which the checked data are saved in CSV format, compatible with most external systems and databases. Thus, we have completed the full cycle of the ETL -process, including extraction, transformation, visualization, documentation and export of data to the systems and formats we need, which ensures reproducibility, transparency and automation of work with information.
ETL – pipeline (pipeline) can be used both for processing single projects and for large-scale application – when analyzing hundreds and thousands of incoming data in the form of documents, images, scans, CAD -projects, point clouds, PDF -files or other sources coming from distributed systems. The ability to fully automate the process makes ETL not just a technical processing tool, but the foundation of a digital construction information infrastructure.





















































{kind=link}
{kind=link}
{kind=link}