

It’s time to move on to building a full-fledged ETL process that covers all key stages of data handling in a single scenario – extraction, transformation and loading. Let’s build an automated ETL-Pipeline that allows you to process PDF documents without manual work – extract data from documents, visualize, analyze and transfer to other systems.
The ETL process in our example will be described through prompts, which will have to explain to the language model (LLM) all the ETL processes with a description of the end result to be obtained. In this case, the task is to find all PDF files in the specified folder and its subfolders, extract relevant information from them – e.g. material names, quantities and costs – and present the result as a structured table (DataFrame) for further analysis
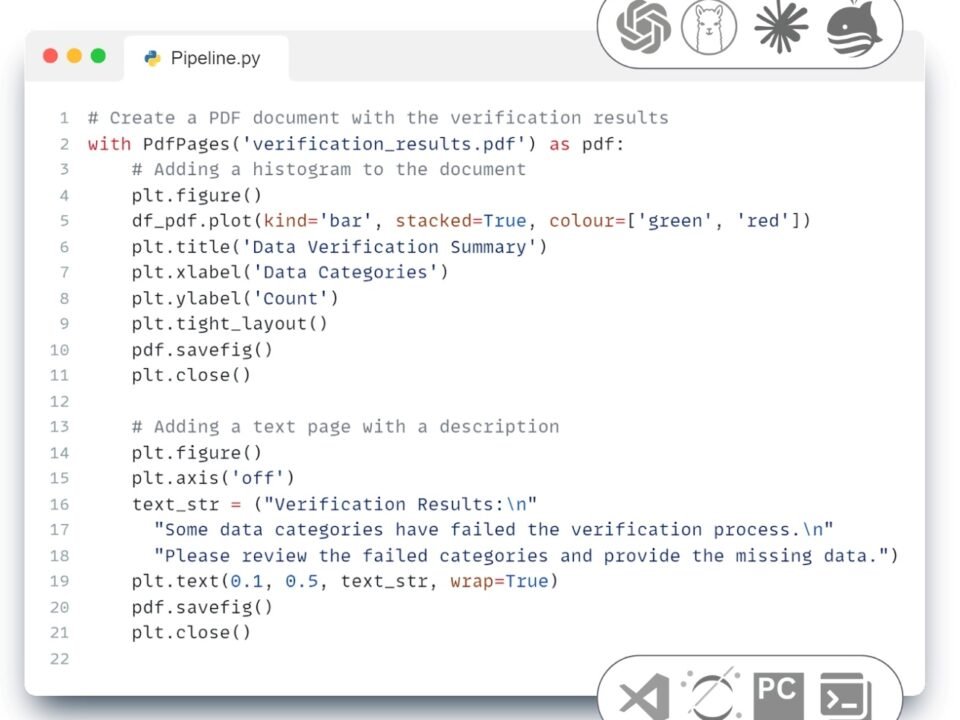
- First text request to LLM to automatically extract data from multiple PDF documents and create a dataframe of the data for the Extract step:
Write code to extract material information from PDF files in a given folder and its subfolders. The data in the PDF includes material name, quantity and cost. The result should be saved in a DataFrame ⏎
 |
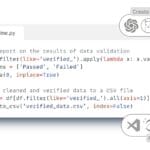
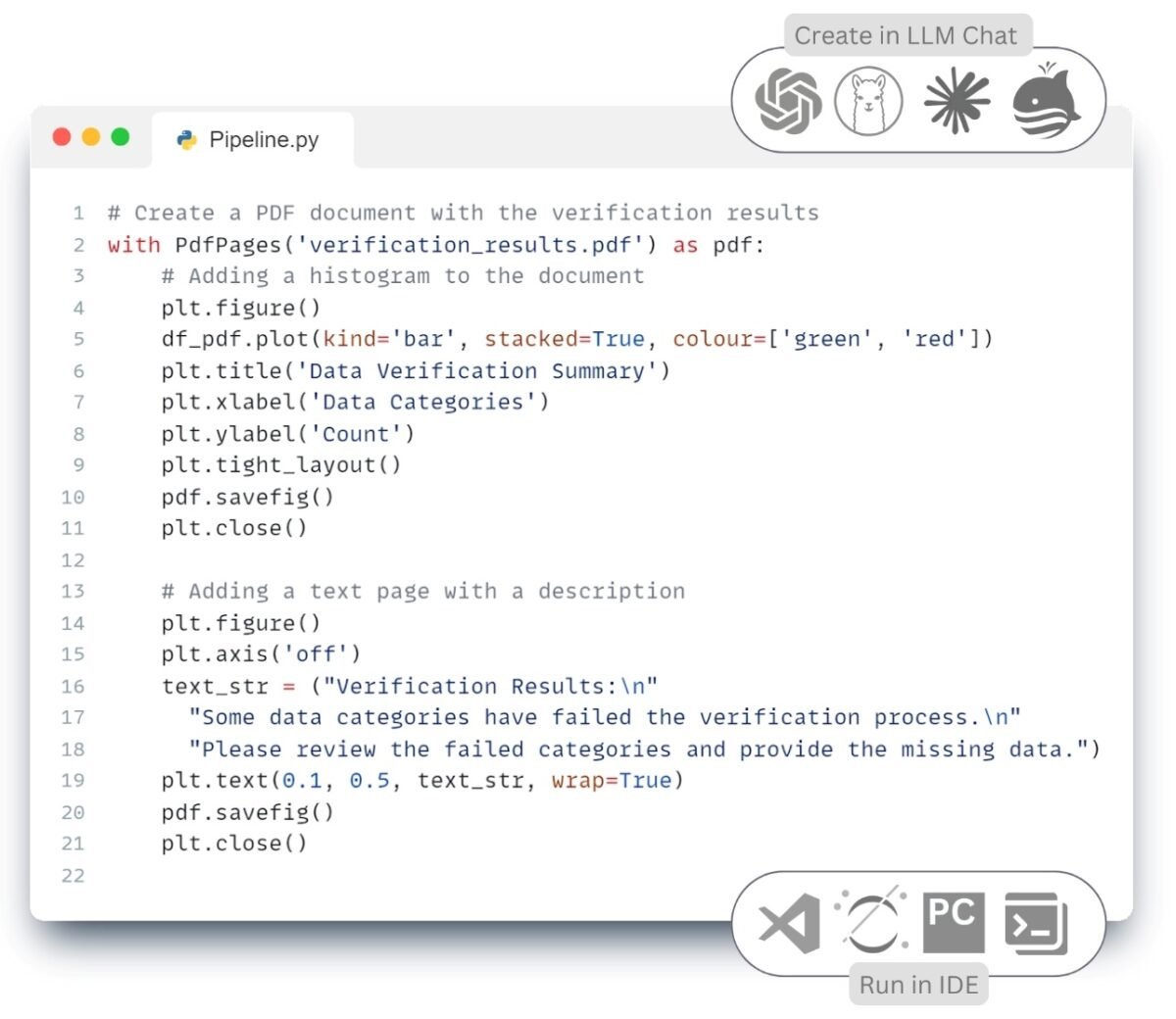
The LLM response (Fig. 7.2-18) is a ready-made Python -script that automatically traverses all folders, opens the found PDF -files, extracts textual information from them and converts it into a table. The resulting chat code can be run in one of the popular IDEs PyCharm, Visual Studio Code (VS Code), Jupyter Notebook, Spyder, Atom, Sublime Text, Eclipse with PyDev plugin, Thonny, Wing IDE, IntelliJ IDEA with Python plugin, JupyterLab or popular online tools Kaggle.com, Google Collab, Microsoft Azure Notebooks, Amazon SageMaker.
Alternatively, to simplify the collection process, instead of copying the code from the LLM and using the code in the IDE, we can also upload a dozen PDF -files directly to the LLM chat room (Fig. 7.2-19) and get a table as output, without having to see the code or run it. The result of executing this code will be a table with the attributes we have selected.

In the next step, we ask for a language model on the obtained data – for example, to compare the cost and volume of material usage and create some visualization examples that will serve as a basis for further analysis.
- Ask in a continuing chat with the LLM to plot some graphs from the tables that were produced in the Transform step (Fig. 7.2-18):
Visualize the total cost and quantity of each material from DataFrame (Fig. 7.2-18⏎

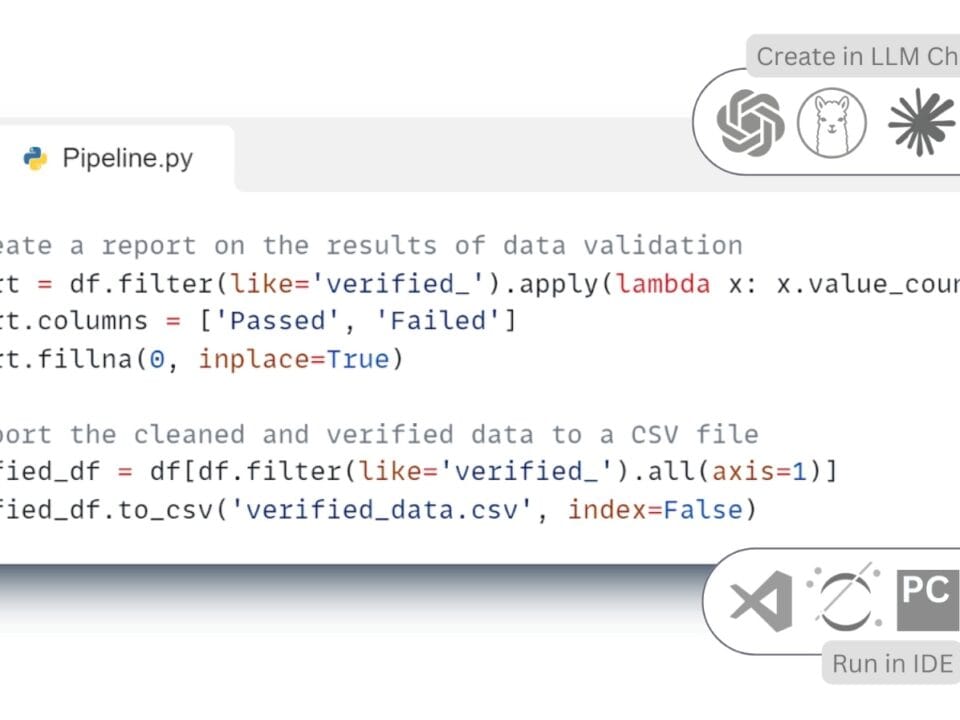
LLM automatically generates and executes Python -code (Fig. 7.2-20) using the matplotlib library. After executing this code, we get graphs of costs and material utilization in construction projects directly in chat (Fig. 7.2-21), which greatly simplifies the analytical work.

Support in developing ideas for writing ETL code, analyzing and executing code, and visualizing results is available through simple text queries in LLM, without the need to learn the basics of programming. The emergence of AI tools such as LLM is definitely changing the approach to programming and automating data processing (Fig. 7.2-22).
According to the PwC report “What is the real value of artificial intelligence for your business and how can you capitalize on it?” (2017) (PWC, “Sizing the prize What’s the real value of AI for your business and how can you capitalize?” 1 January 2017), process automation and productivity improvements will be the main drivers of economic growth. And productivity improvements are expected to account for more than 55% of all AI-driven GDP growth between 2017 and 2030.”

Using tools like ChatGPT, LlaMa, Mistral, Claude, DeepSeek, QWEN, Grok, as well as open data and open source software, we can automate processes that were previously only done with specialized, high-cost and difficult to maintain modular proprietary systems.
In the construction context, this means that companies that are the first to implement automated Pipeline -data processes will realize significant benefits, from increased project management efficiency to reduced financial losses to the elimination of fragmented applications and siloed data warehouses.
The described logic of executing business tasks in the ETL process is a crucial part of automating analytics and data processing processes, which is a specific variation of a broader concept – pipelines (Pipelines).





















































{kind=link}
{kind=link}
{kind=link}