
Apache Airflow is widely used to organize complex data processing processes, allowing to build flexible ETL -conveyors. Apache Airflow can be run either through a web interface or programmatically through Python code (Fig. 7.4-2). In the web interface (Fig. 7.4-3), administrators and developers can visually track DAGs, run tasks, and analyze execution results.
Using DAG, you can set a clear sequence of tasks, manage dependencies between them and automatically react to changes in the source data. Let’s consider an example of using Airflow to automate reporting processing (Fig. 7.4-2).

This example (Fig. 7.4-2) considers the DAG, which performs key tasks within the ETL -conveyor:
- Read Excel -files (Extract):
– Sequential traversal of all files in a given directory.
– Read data from each file using the pandas library.
– Combining all data into a single DataFrame. - Create PDF -document (Transform):
– Transform the merged DataFrame into an HTML -table.
– Save the table as PDF (in the demo version – via HTML). - Sending a report by e-mail (Load):
– Apply EmailOperator to send PDF -document by email. - Customizing DAG:
– Defining the sequence of tasks: extracting data→ generating report→ sending.
– Assigning a launch schedule (@monthly – first day of each month).
The automated ETL -example (Fig. 7.4-2) shows how to collect data from Excel -files, create a PDF -document, and email it. This is just one of many possible use cases for Airflow. This example can be adapted to any specific task to simplify and automate data processing.

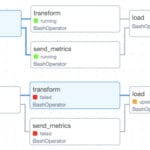
The Apache Airflow web interface (Fig. 7.4-3) provides a comprehensive visual environment for managing data workflows. It displays DAGs as interactive graphs, with nodes representing tasks and edges representing dependencies between them, making it easy to keep track of complex data workflows. The interface includes a dashboard with information on task execution status, run history, detailed logs, and performance metrics. Administrators can manually start tasks, restart failed operations, suspend DAGs, and customize environment variables, all through an intuitive user interface.
Such architecture can be supplemented with data validation, notifications on execution status, integration with external APIs or databases. Airflow allows flexible customization of DAG: add new tasks, change their order, combine chains – which makes it an effective tool for automating complex data processing. When running DAG in the Airflow web interface (Fig. 7.4-3, Fig. 7.4-4), you can monitor the status of task execution. The system uses color indication:
- Green – the task has been successfully completed.
- Yellow – the process is in progress.
- Red – an error while performing the task.
In case of failures (e.g., missing file or broken data structure), the system automatically initiates sending a notification.

Apache Airflow is convenient because it automates routine tasks, eliminating the need to perform them manually. It provides reliability by monitoring process execution and instant error notification. The flexibility of the system makes it easy to add new tasks or modify existing ones, adapting workflows to meet changing requirements.
In addition to Apache Airflow, there are similar tools for orchestrating workflows. For example the open source and free Prefect (Fig. 7.3-5) offers a simpler syntax and integrates better with Python, Luigi, developed by Spotify, provides similar functionality and works well with big data. Also worth noting are Kronos and Dagster, which offer modern approaches to building Pipeline with a focus on modularity and scalability. The choice of task orchestration tool depends on the specific needs of the project, but they all help automate complex ETL data processes
Of particular note is Apache NiFi, an open source platform, designed for streaming and routing data. Unlike Airflow, which focuses on batch processing and dependency management, NiFi focuses on real-time, on-the-fly data transformation and flexible routing between systems.





















































{kind=link}