

One of the popular formats for storing and processing big data is Apache Parquet. This format is designed specifically for columnar storage (similar to Pandas), which allows you to significantly reduce memory footprint and increase the speed of analytical queries. Unlike traditional formats such as CSV and XLSX, Parquet supports native compression and is optimized for big data systems including Spark, Hadoop, and cloud storage.
Key features of Parquet include support for data compression and encoding, which significantly reduces storage size and speeds up data read operations by working directly with the desired columns rather than all rows of data.
For an illustrative example of how easy it is to get the necessary code to convert data to Apache Parquet, let’s use the LLM.
- Send a text request to LLM chat (CHATGP, LlaMa, Mistral DeepSeek, Grok, Claude, QWEN):
Write code to save data from Pandas DataFrame to Apache Parquet. ⏎
 |
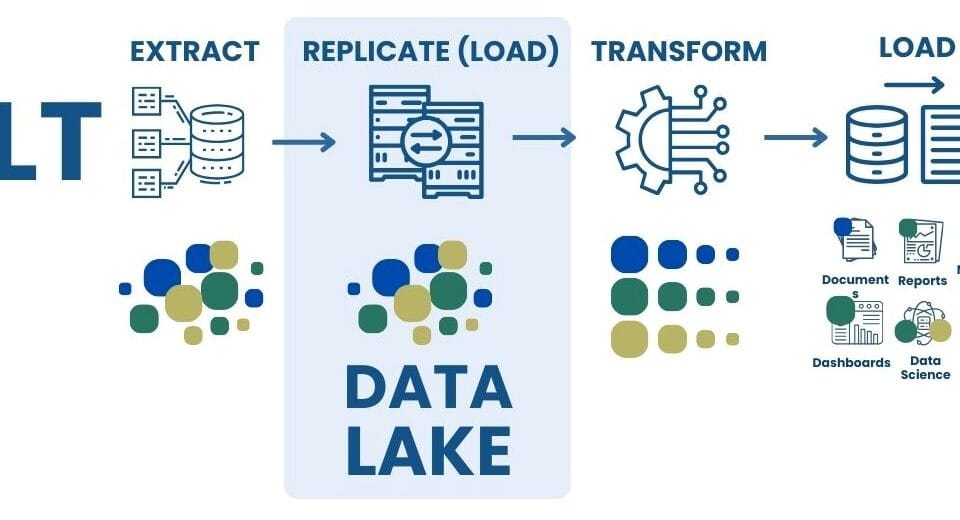
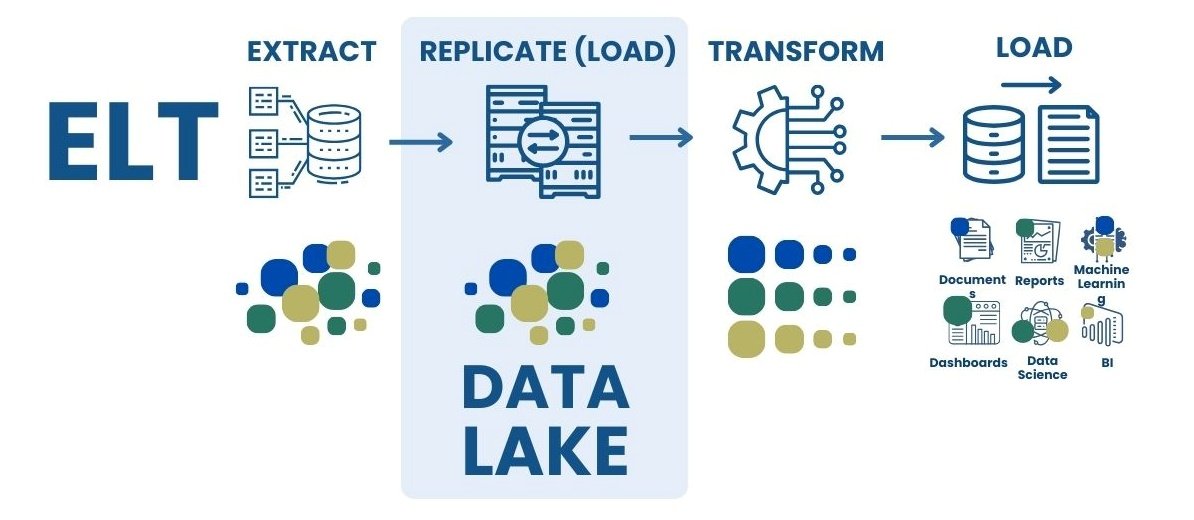
Next example: let’s simulate the ETL process with data stored in Parquet format to filter projects by a certain value of one of the attributes “cost_million_usd” (Fig. 8.1-4).
- As the chat continues, send a text request to LLM:
Write code where we want to filter the data in a table and save only those projects (table rows) from Apache Parquet data, whose cost (parameter cost_million_usd) exceeds 150 million dollars. ⏎
|

Using the Parquet format (in relation to XLSX, CSV, etc.) significantly reduces the amount of information stored and speeds up search operations. This makes it excellent for both storing and analyzing data. Parquet integrates with various processing systems, providing efficient access in hybrid architectures.
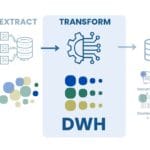
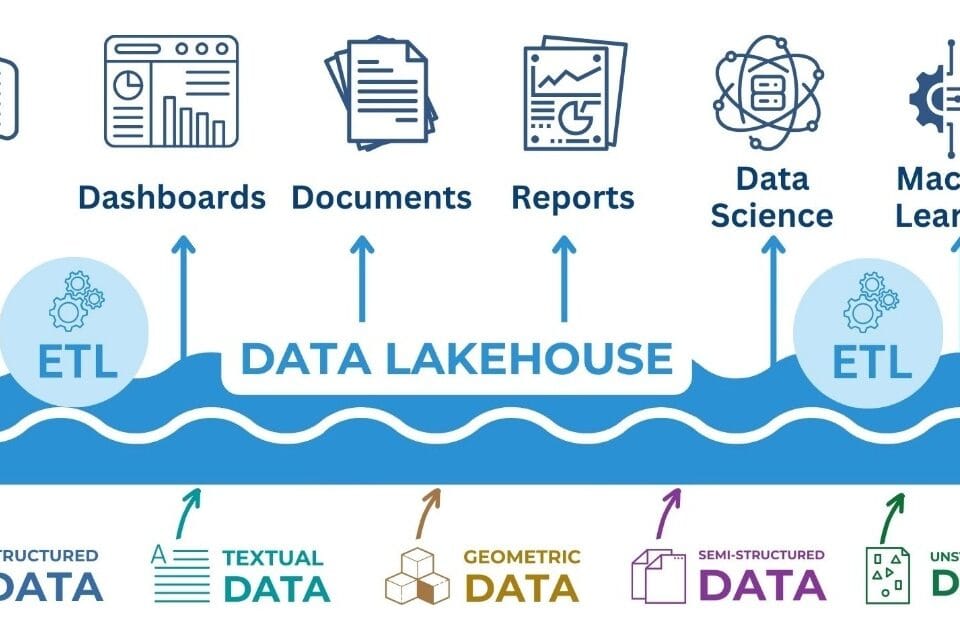
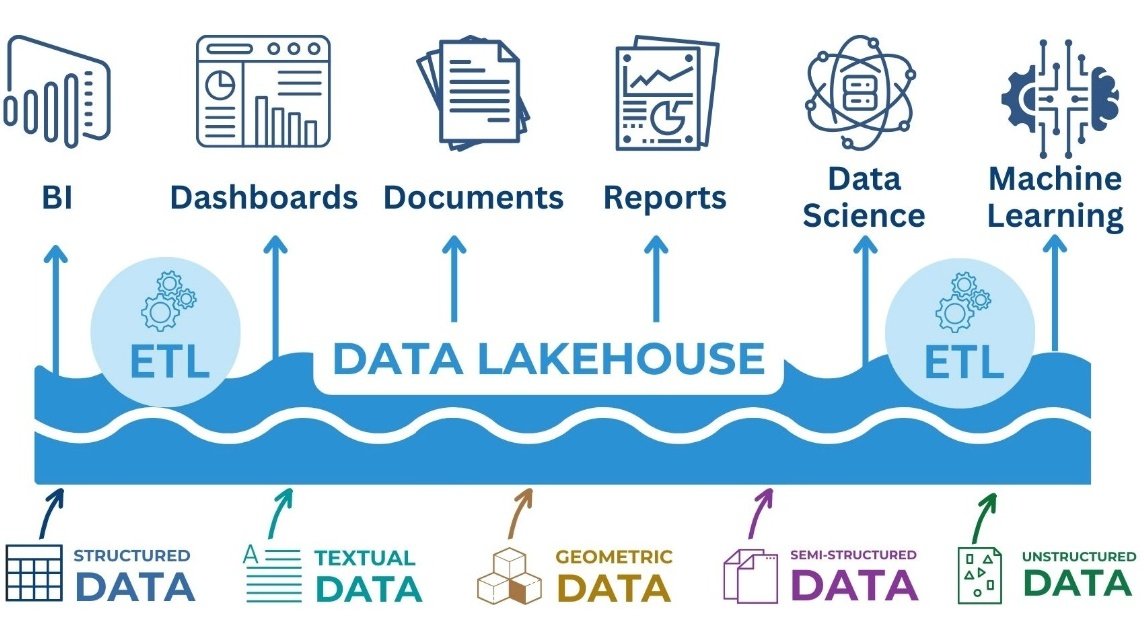
However, an efficient storage format is only one element of a complete data experience. To create a sustainable and scalable environment, a well-designed data management architecture is required. This is exactly what DWH (Data Warehouse) class systems do. They provide aggregation of data from heterogeneous sources, transparency of business processes and the possibility of complex analysis using BI-tools and machine learning algorithms.




















































{kind=link}
{kind=link}