
Classic DWH – data warehouses, designed to store structured data in a format optimized for analytical queries, have faced limitations in handling unstructured data and scalability. In response to these challenges, Data Lakes) have emerged, offering flexible storage for large amounts of heterogeneous data.
Data Lake offers an alternative DWH -approach that allows working with unstructured, semi-structured and raw data without a prior hard schema. This storage method is often relevant for real-time data processing, machine learning and advanced analytics. Unlike DWH, which structures and aggregates data before loading, Data Lake allows information to be stored in its raw form, thus providing flexibility and scalability
It was frustration with traditional data warehouses (RDBMS, DWH) and interest in “big data” that led to the emergence of data lakes, where instead of complex ETL, data is now simply loaded into a loosely structured repository, and its processing takes place already at the analysis stage:
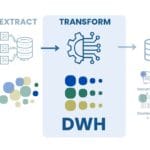
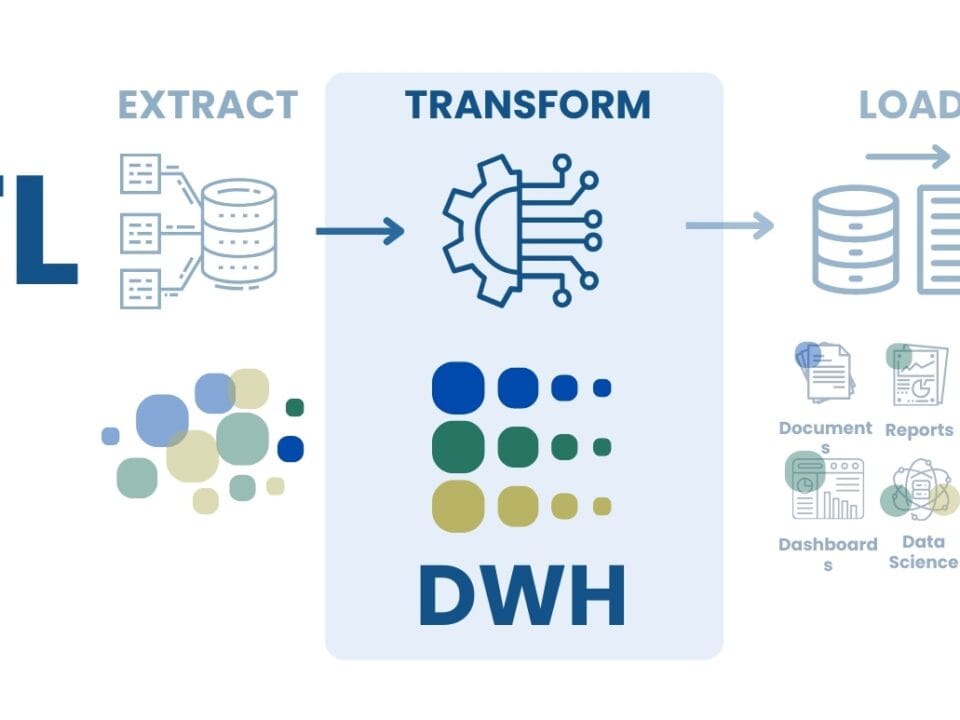
In traditional data warehouses, data is typically pre-processed, transformed and cleaned (ETL – Extract, Transform, Load) before being loaded into the warehouse (Fig. 8.1-6). This means that data is structured and optimized for specific future analytics and reporting tasks. The emphasis is on maintaining high query performance and data integrity. However, this approach can be costly and less flexible in terms of integrating new data types and rapidly changing data schemas.
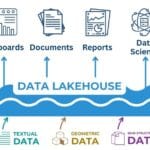
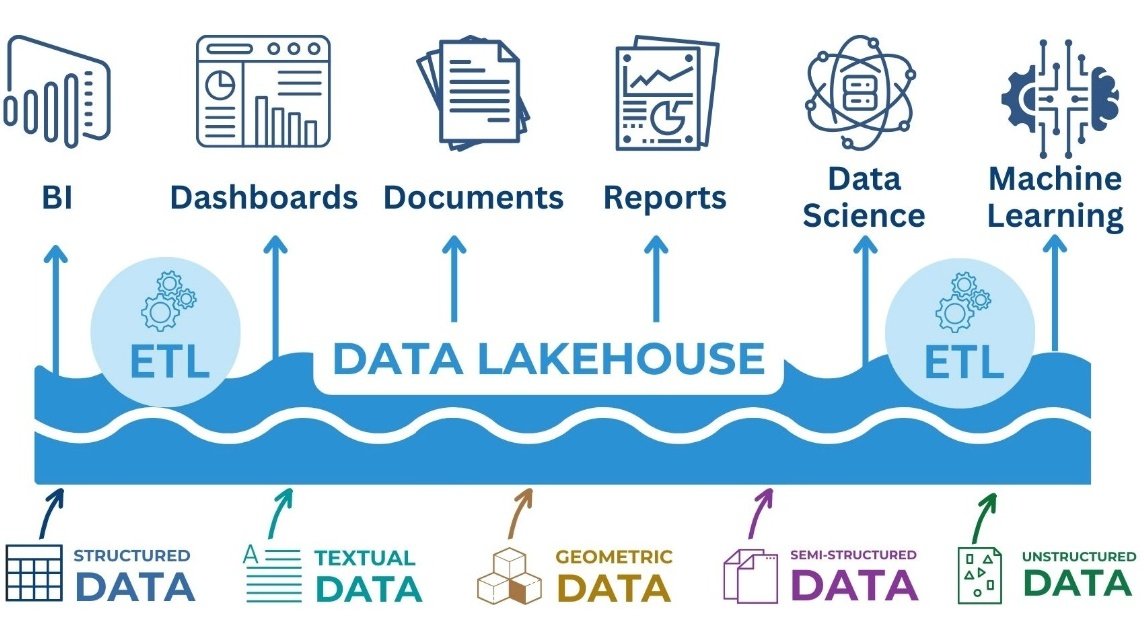
Data lakes, on the other hand, are designed to store large amounts of raw data in its original format (Fig. 8.1-7). The ETL (Extract, Transform, Load), process is being replaced by ELT (Extract, Load, Transform), where data is first loaded into storage “as is” and only then can be transformed and analyzed as needed. This provides greater flexibility and the ability to store heterogeneous data, including unstructured data such as text, images and logs.

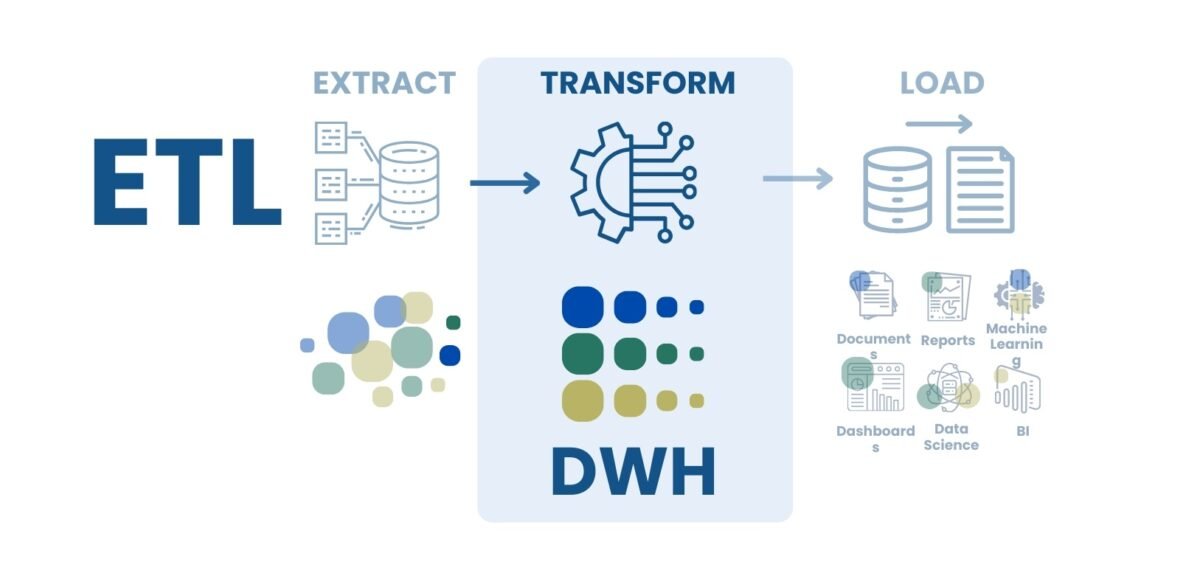
Traditional data warehouses focus on pre-processing data for high query performance, while data lakes prioritize flexibility: they store raw data and transform it as needed (Fig. 8.1-8).

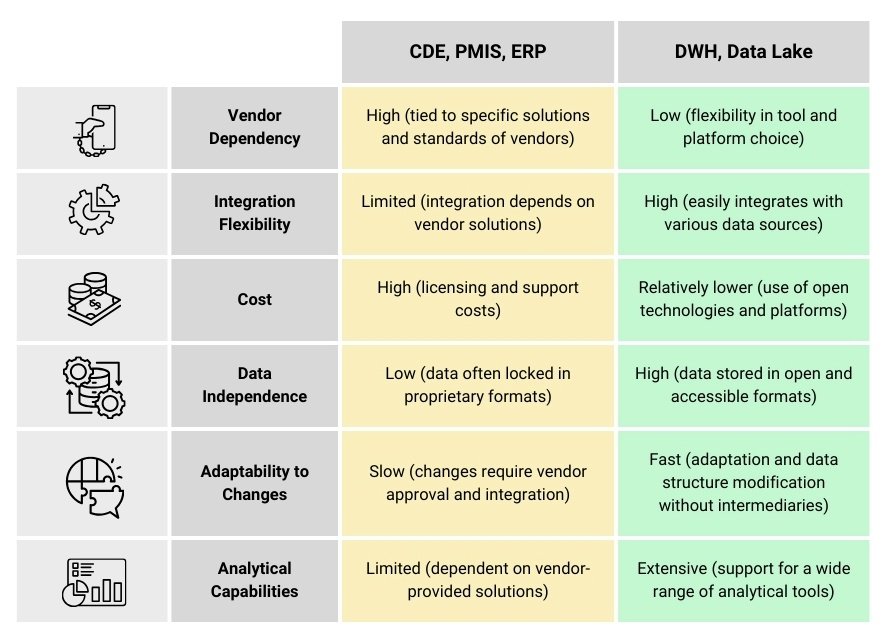
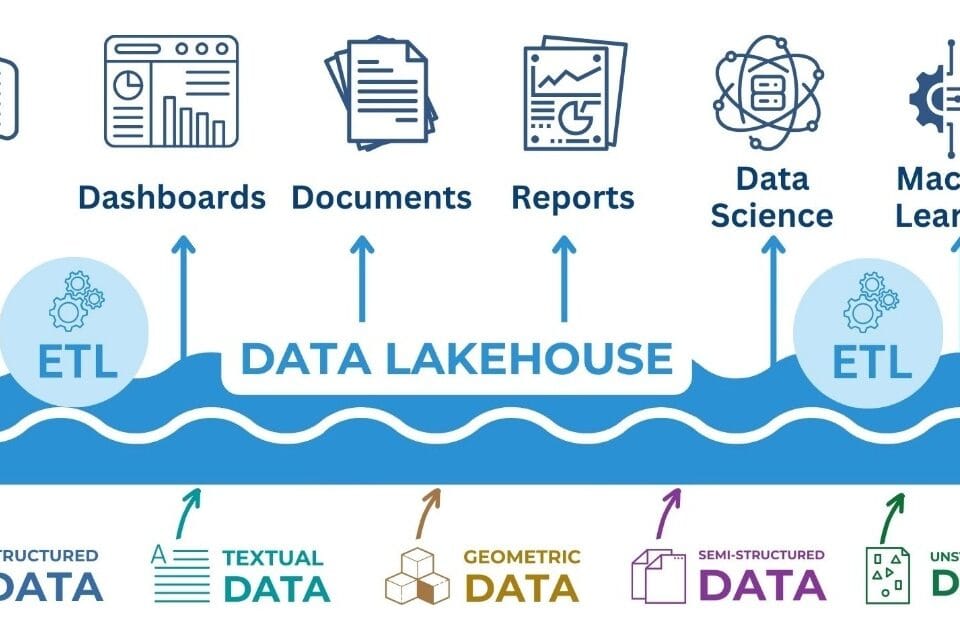
However, despite all the advantages and data lakes are not without disadvantages. The lack of a strict structure and the complexity of information management can lead to chaos in which data is duplicated, contradicts each other or loses its relevance. In addition, searching and analyzing data in such a repository requires considerable effort, especially when dealing with heterogeneous information. To overcome these limitations and combine the best features of traditional data warehouses and data lakes, the Data Lakehouse architecture was developed.




















































{kind=link}
{kind=link}