

Vector databases are a new class of repositories that do not just store data, but allow searching by meaning, comparing objects by semantic proximity, and creating intelligent systems: from recommendations to automatic analysis and context generation. Unlike traditional databases that focus on exact matches, vector databases find similar objects based on attributes – even if there is no exact match
A vector database is a specialized type of database that stores data as multidimensional vectors, each representing certain characteristics or qualities. These vectors can have different numbers of dimensions, depending on the complexity of the data (in one case it may be a few dimensions, and in another ー thousands).
The main advantage of vector databases is search by semantic relevance rather than by exact matching of values. Instead of SQL- and Pandas -queries with “equals” or “contains” filters, the search of nearest neighbors (k-NN) (we will talk more about k-NN in the next part of the book) in the feature space is used.
With the development of LLM (Large Language Models) and generative models, interaction with databases is beginning to change. It is now possible to query data in natural language, get semantic searches on documents, automatically extract key terms, and build contextual relationships between objects – all without the need for SQL proficiency or knowledge of table structure. This was discussed in more detail in the section “LLMs and their role in data processing and business processes”.
However, it is important to realize that LLMs do not automatically structure and organize information. The model just floats through the data and finds the most relevant piece of data based on the context of the query. If the data has not been pre-cleaned or transformed, deep search will be like trying to find an answer in digital “garbage” – it may work, but the quality of results will be lower. Ideally, if the data can be structured (e.g., translate documents into Markdown) and loaded into a vector database. This significantly increases the accuracy and relevance of the output.
Initially, vector databases were used in machine learning, but today they find more and more applications outside of it – in search engines, content personalization, and intelligent analytics.
One of the most obvious examples of the vector approach in construction is the Bounding Box (bounding parallelepiped). It is a geometric construction that describes the boundaries of an object in three-dimensional space. The Bounding Box is defined by the minimum and maximum X, Y and Z coordinates, forming a “box” around the object. This method allows you to estimate the size and placement of an element without having to analyze the entire geometry.
Each Bounding Box can be represented as a vector in a multidimensional space: for example, [x, y, z, width, height, depth] – already 6 dimensions (Fig. 8.2-1).Formularbeginn

This data representation facilitates many tasks, including checking for intersections between objects, planning the spatial distribution of building elements, and performing automated calculations. Bounding Box can serve as a bridge between complex 3D models and traditional vector databases, allowing you to effectively use the advantages of both approaches in architectural and engineering modeling
Bounding Box is “vectorization of geometry”, and embedding (a way of transforming something abstract) is “vectorization of meaning”. Both approaches allow you to move from manual search to intelligent search, be it 3D -objects in a project model or concepts in a text.
Search of objects in the project (for example, “find all windows with width > 1.5 m”) is similar to the search of nearest neighbors (k-NN) in a vector database, where the criteria define a “zone” in the feature space. (we will talk more about k-NN nearest neighbors search in the next part about machine learning) (Fig. 8.2-2). If we add additional parameters (material, weight, production time) to the bounding box attributes, the table turns into a high-dimensional vector, where each attribute is a new dimension. This is closer to modern vector bases, where dimensions are counted in hundreds or thousands (e.g., embedding from neural networks).

Formularende
The approach used in Bounding Box, is applicable not only to geometric objects, but also to text and language analysis. Vector representations of data are already actively used in natural language processing (NLP). Just as objects in a construction project can be grouped by spatial proximity (Fig. 8.2-2), words in text can be analyzed by their semantic and contextual proximity.
For example, the words “architect”, “construction”, “design” will be next to each other in vector space because they have a similar meaning. In LLM this mechanism allows automatic, no manual categorization required:
- Identify the subject matter of a text
- Perform semantic searches on the content of documents
- Generate automatic annotations and summaries of text
- Find synonyms and related terms
Vector databases allow you to analyze text and find related terms in it in the same way that Bounding Box helps you analyze spatial objects in 3D -models. The example of Bounding Box of project elements helps to understand that vector representation is not a purely “artificial” concept from ML, but a natural way of structuring data for solving applied problems, whether it is searching for columns in a CAD project or semantically close images in a database.
Specialists working with databases should pay attention to vector stores. Their proliferation indicates a new stage in database development, where classical relational systems and AI -oriented technologies begin to intertwine, forming hybrid solutions of the future.
Users developing complex and large-scale AI -applications will use specialized databases for vector search. At the same time, those who need only separate AI-functions for integration into existing applications are more likely to choose built-in vector search capabilities in the databases they already use (PostgreSQL, Redis).
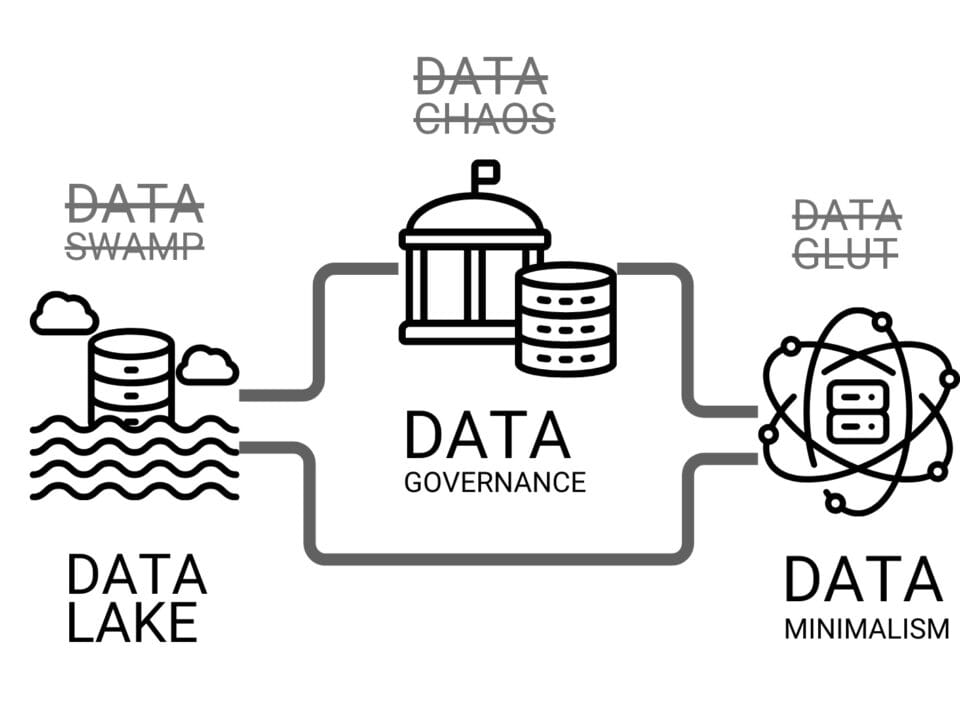
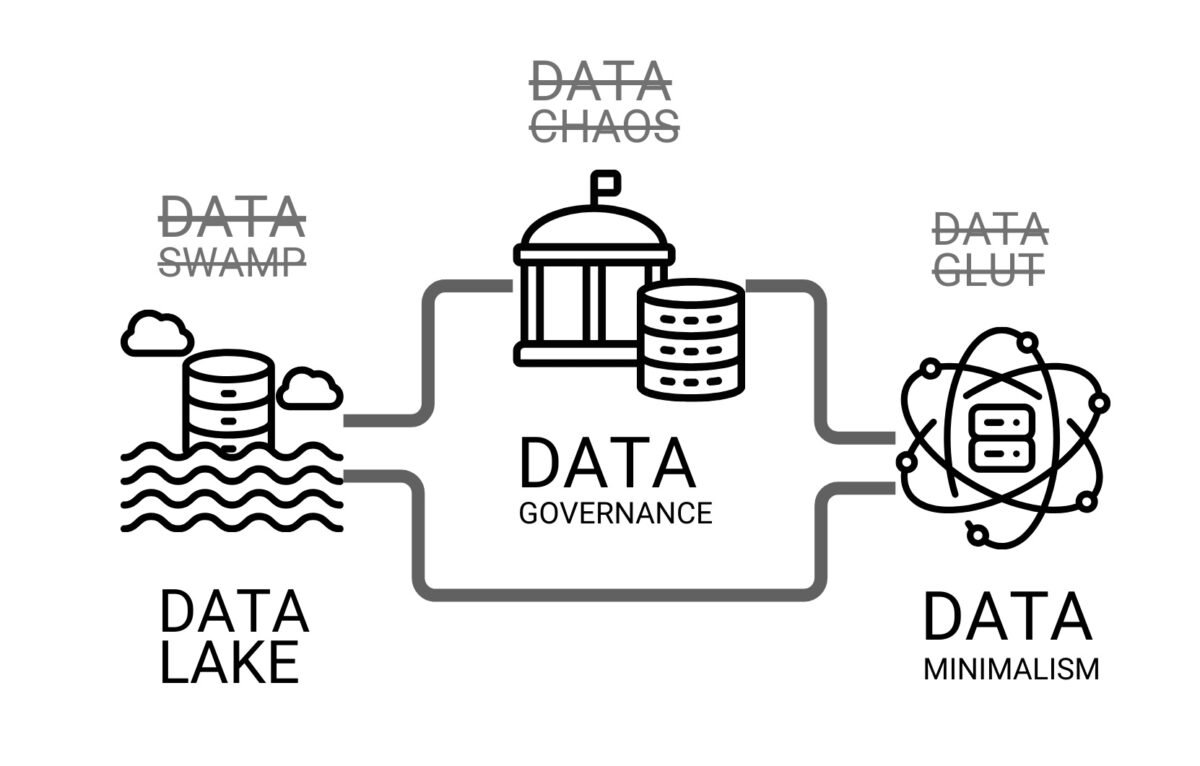
Although systems such as DWH, Data Lake, CDE, PMIS, vector databases and others offer different approaches to storing and managing data, their effectiveness is determined not only by their architecture, but also by how well the data itself is organized and managed. Even when using modern solutions – be it vector databases, classical relational DBMSs or Data Lake-type warehouses – the lack of clear rules for managing, structuring and updating data can lead to the same difficulties faced by users working with disparate files and multi-format data.
Without Data Governance), even the most powerful solutions can become chaotic and unstructured data, turning data lakes into Data Swamps). To avoid this, companies must not only choose the right storage architecture, but also implement Data Minimalism), access management and quality control strategies to turn data into an effective decision-making tool.




















































{kind=link}