
Understanding and implementing the concepts of Data Governance, Data Minimalism, and preventing Data Swamp are key to successfully managing data warehouses and delivering business value (Fig. 8.2-3).
According to a study by Gartner (2017), 85% of big data projects fail, and one of the key reasons is insufficient data quality and data governance(B. T. O’Neill, “Failure rates for analytics, AI, and big data projects = 85% – yikes!,” 1 Jan. 2025).

Data Governance (Data Governance) is a fundamental component of data management, ensuring that data is used appropriately and effectively in all business processes. It is not only about establishing rules and procedures, but also about ensuring the availability, reliability and security of data:
Defining and classifying data: clearly defining and classifying entities allows organizations to understand what entities are needed in the company and determine how they should be used.
Access rights and management: developing policies and procedures for data access and management ensures that only authorized users can access certain data.
Protecting data from external threats: Protecting data from external threats is a key aspect of data management. This includes not only technical measures, but also training of employees in the basics of information security.
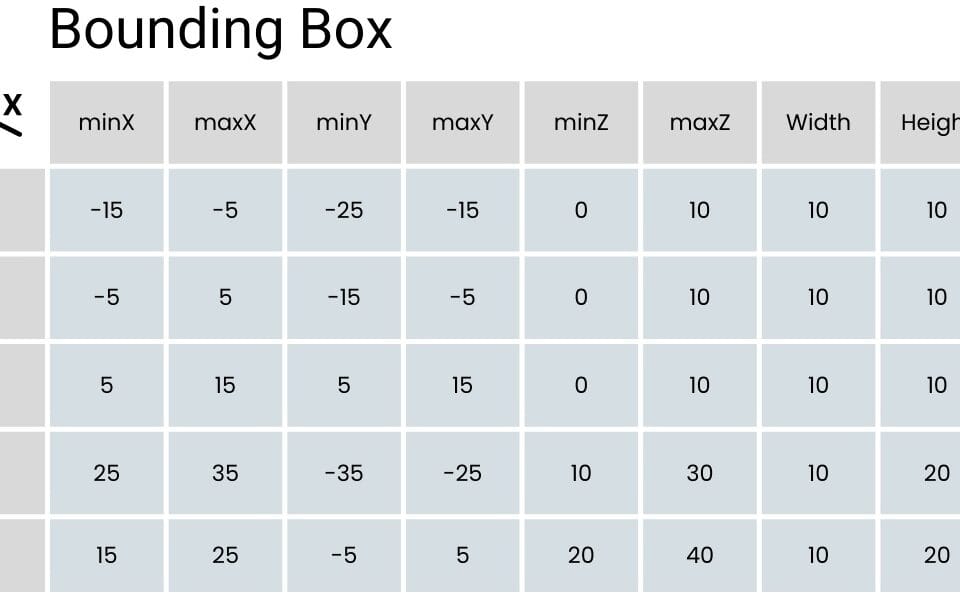
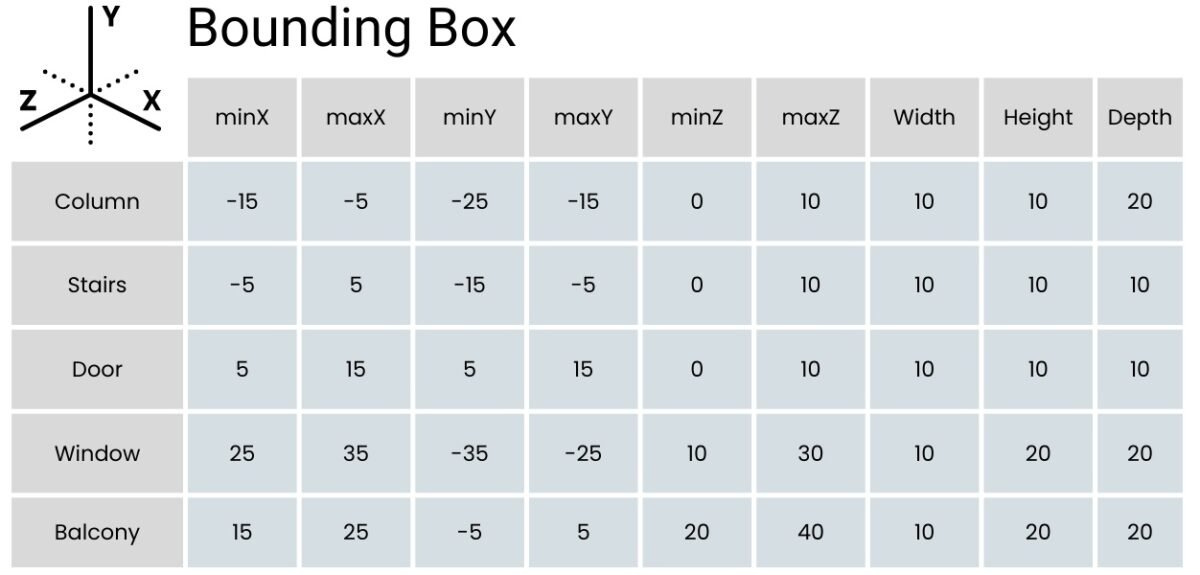
Data Minimalism is an approach to reduce data to the most valuable and meaningful attributes and entities in the formation (Fig. 8.2-4), thereby reducing costs and improving data utilization:
Simplifying decision making: reducing the number of objects and their attributes to the most relevant simplifies the decision making process by reducing the time and resources required to analyze and process data.
Focusing on what’s important: selecting the most relevant entities and attributes allows you to focus on the information that really matters to the business, eliminating noise and unnecessary data.
Efficient resource allocation: data minimization enables more efficient resource allocation, reducing data storage and processing costs, improving data quality and security.
The logic of working with data should not start with its creation as such (Fig. 8.2-4), but with understanding of future scenarios of using this data even before the generation process starts. This approach allows to determine in advance the minimum necessary requirements for attributes, their types and boundary values. These requirements form the basis for creating correct and stable entities in the information model. Preliminary understanding of the purposes and uses of the data contributes to the formation of a suitable structure for analysis. More details about approaches to data modeling at the conceptual, logical and physical levels were discussed in the chapter “Data modeling: conceptual, logical and physical model”.
In the traditional business processes of construction companies, data processing more often resembles dumping data into a swamp, where data is first created and then specialists try to integrate it into other systems and tools.
Data Swamp is the result of uncontrolled collection and storage of data without proper organization, structuring and management, resulting in data that is unstructured, difficult to use and of little value.
How to prevent the flow of information from becoming a quagmire:
Data structure management: ensuring that data is structured and categorized helps prevent data swamping by making it organized and easily accessible.
Understanding and interpreting data: a clear description of data origins, modifications and meanings ensures that data are understood and interpreted correctly.
Maintaining data quality: regular data maintenance and cleansing helps maintain data quality, relevance, and value for analytics and business processes.

By integrating the principles of data governance and data minimalism into data management processes, and actively preventing data warehouses from becoming data swamps, organizations can maximize the potential of their data.
The next stage in the evolution of working with data, after solving the issues of management and minimalism, is the standardization of automatic processing, quality assurance and the implementation of methods that make data usable for analysis, transformation and decision-making. This is what the DataOps and VectorOps methodologies are doing, which are becoming important tools for companies working with big data and machine learning.




















































{kind=link}