
While Data Governance is responsible for controlling and organizing data, DataOps helps ensure its accuracy, consistency and smooth flow within the company. This is especially critical for a number of business cases in construction, where data is generated continuously and requires timely processing. For example, in situations where building information models, project requirements and analytical reports need to be synchronized between different systems within a single business day, the role of DataOps can be key. It allows you to build stable and repeatable data processing processes, reducing the risk of delays and loss of relevance of information.
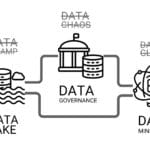
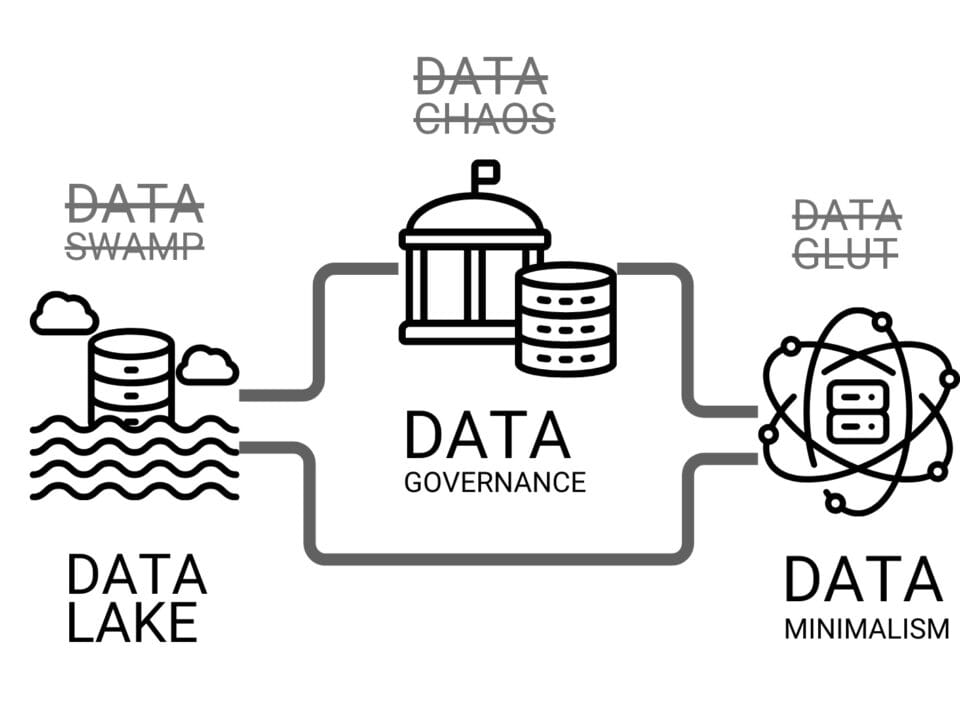
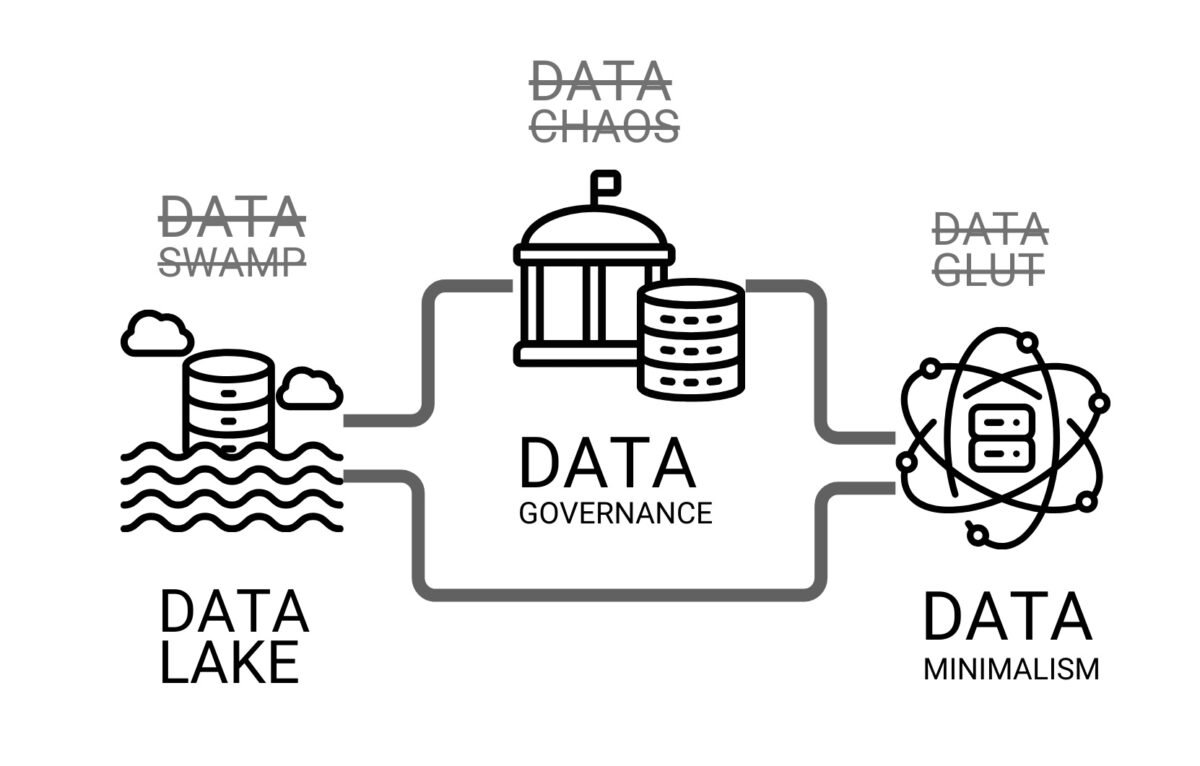
Data Governance alone is not enough – it is important that data is not just stored, but actively used in daily operations. This is where DataOps – a methodology focused on automation, integration and continuous data flow – comes to the fore.
DataOps focuses on improving collaboration, integration, and automation of data flows in organizations. Adopting DataOps practices promotes data accuracy, consistency, and availability, which is critical for data-centric applications.
Key tools in the DataOps ecosystem are Apache Airflow (Fig. 7.4-4) for workflow orchestration, and Apache NiFi (Fig. 7.4-5) for routing and transforming data flows. Together, these technologies enable flexible, reliable, and scalable data pipelines, enabling automatic processing, control, and integration of information between systems (more details in the chapter “Automatic ETL -conveyor “). When implementing the DataOps approach in construction processes, it is important to consider four fundamental aspects:
People and tools are more important than data: siloed data repositories may be seen as a major problem, but the reality is more complex. In addition to data fragmentation, the isolation of teams and the disparate tools they use play a significant role. In construction, specialists from different disciplines work with data: data engineers and analysts, BI and visualization teams, and project management and quality experts. Each of them has different ways of working, so it becomes important to create an ecosystem where data flows freely between participants, providing a single, consistent version of information.
Automate testing and error detection: Construction data always contains errors, be it inaccuracies in models, calculation errors or outdated specifications. Regularly testing data and eliminating recurring errors can significantly improve data quality. As part of DataOps, you need to implement automated controls and validation mechanisms that monitor data correctness, analyze errors and identify patterns, and capture and address system failures in every workflow. The higher the degree of automated validation, the higher the overall data quality and the lower the likelihood of errors in the final stages.
Data should be tested in the same way as program code: most building applications are based on data processing, but its control is often left to secondary roles. If machine learning models are trained on inaccurate data, it leads to incorrect predictions and financial losses. As part of DataOps, data should be subjected to the same scrutiny as software code: logic checks, stress tests, and evaluation of model behavior when input values change. Only validated and reliable data can be used as the basis for management decisions.
Data observability without sacrificing performance: data monitoring is not just a collection of metrics, but a strategic quality management tool. For DataOps to work effectively, observability must be built in at all stages of data handling, from design to operation. At the same time, it is important that monitoring does not slow down the system. In construction projects, it is critical to not only collect data, but to do so in such a way that the work of the professionals (e.g. designers) creating the data is not disrupted in any way. This balance allows you to control data quality without sacrificing productivity.
DataOps is not an additional burden for data scientists, but the backbone of their work. By implementing DataOps, construction companies can move from chaotic data management to an efficient ecosystem where data works for the business.
In turn, VectorOps represents the next stage in the evolution of DataOps, focused on processing, storing, and analyzing multidimensional vector data (which were discussed in the previous chapter). This is particularly relevant in areas such as digital twins, neural network models and semantic search, which are starting to come to the construction industry. VectorOps relies on vector databases to efficiently store, index, and search multidimensional representations of objects.
VectorOps is the next step after DataOps, focused on processing, analyzing and using vector data in construction. Unlike DataOps, which focuses on data flow, consistency and quality, VectorOps focuses on managing the multidimensional object representations needed for machine learning.
Unlike traditional approaches, VectorOps allows you to achieve more accurate object descriptions, which is critical for digital twins, generative design systems, and automatic error detection in CAD data converted to vector format. The combined implementation of DataOps and VectorOps forms a solid foundation for scalable, automated work with large volumes of information – from classic tables to semantically rich spatial models




















































{kind=link}
{kind=link}