
The data collected on the company’s projects opens up the possibility of building models capable of predicting the cost and time characteristics of future, not yet realized objects – without time-consuming manual calculations and comparisons. This makes it possible to significantly speed up and simplify valuation processes, relying not on subjective assumptions, but on sound mathematical forecasts.
Earlier, in the fourth part of the book, we have considered in detail traditional methods of project cost estimation, including the resource-based method, and also mentioned parametric and expert approaches. These methods are still relevant, but in modern practice they are beginning to be enriched with tools of statistical analysis and machine learning, which allows to significantly improve the accuracy and reproducibility of estimates.
The processes of manual and semi-automatic calculation of prices and temporal attributes will in the future be complemented by the opinion and predictions of ML models capable of analyzing historical data, finding hidden patterns and offering informed decisions. New data and scenarios will be generated automatically from already available information – similar to how language models (LLM)create texts, images and code based on data collected over the years from open sources (Ш. Johri, “Creating ChatGPT: From Data to Dialogue,” 2024).
Just as humans today rely on experience, intuition and internal statistics to assess future events, in the coming years the future of construction projects will be increasingly determined by a combination of accumulated knowledge and mathematical machine learning models.

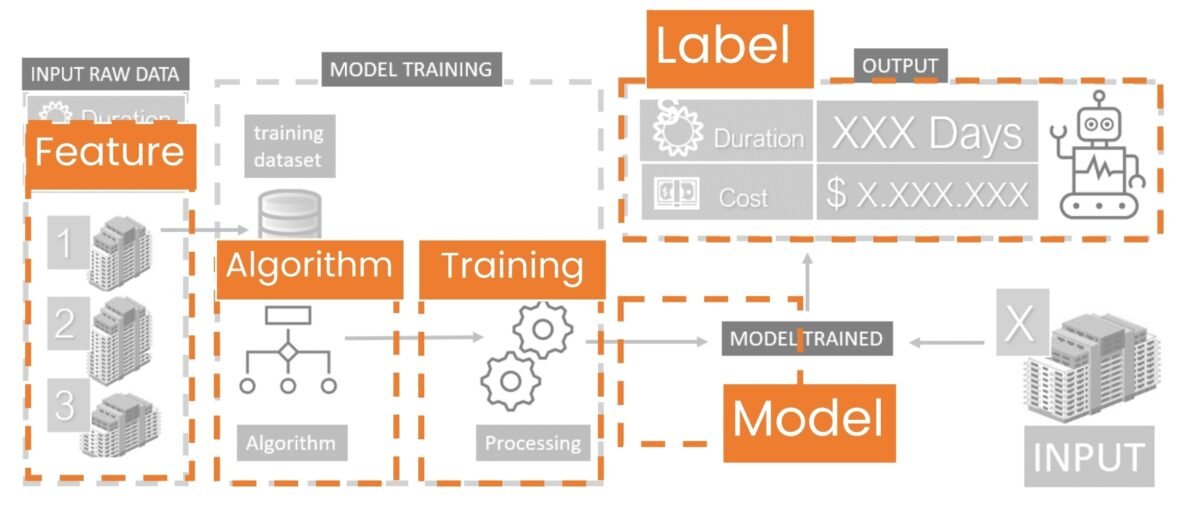
Consider a simple example: predicting the price of a house based on its area, plot size, number of rooms and geographical location. One approach is to build a classical model that analyzes these parameters and calculates the expected price (Fig. 9.2-13). This approach requires a precise and known formula in advance, which is practically impossible in real practice.

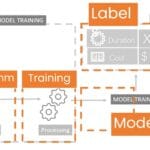
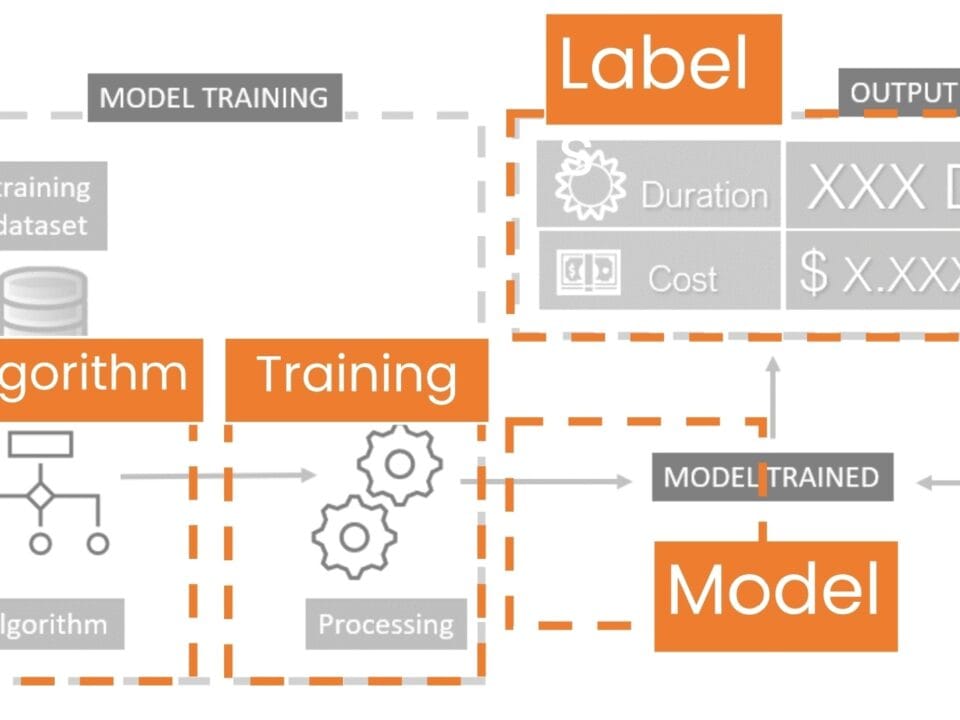
Machine learning eliminates the manual search for formulas and replaces them with trained algorithms that independently identify dependencies that are many times more accurate than any predetermined equations. Alternatively, let’s create a machine learning algorithm, which will generate a model based on a prior understanding of the problem and historical data that may be incomplete (Fig. 9.2-14).
Using the pricing problem as an example, machine learning allows you to create different types of mathematical models that do not require knowledge of the exact mechanism of cost formation. The model “learns” from the data on previous projects, adjusting to real patterns between building parameters, their cost and deadlines.

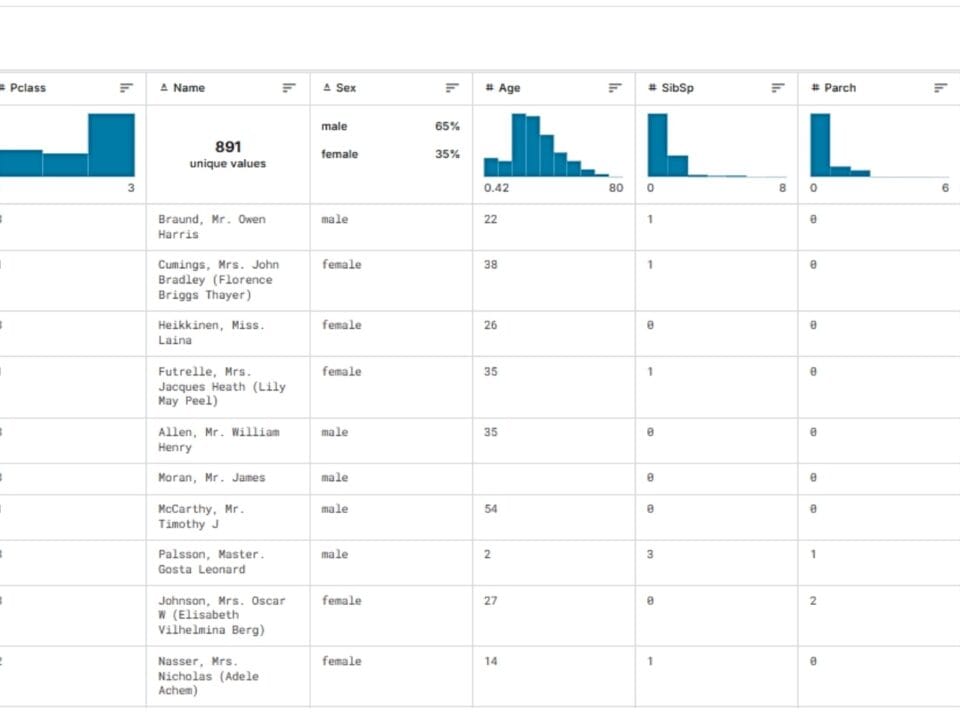
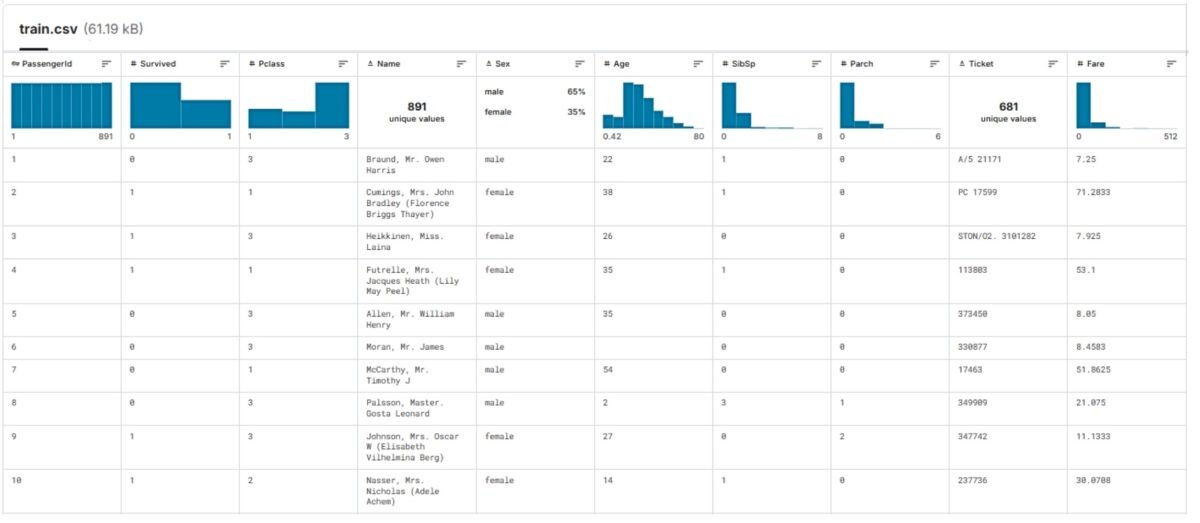
In the context of supervised machine learning, each project in the training dataset contains both input attributes (e.g. cost and time data for similar buildings) and expected output values (e.g. cost or time). A similar dataset is used to create and customize a machine learning model (Fig. 9.2-15). The larger the dataset and the higher the quality of the data in it, the more accurate the model will be and the more accurate the prediction results will be.

Once the model is created and trained to estimate the construction of a new project, simply provide the model with new attributes for the new project, and the model will provide estimated results based on previously learned patterns with some probability.




















































{kind=link}
{kind=link}
{kind=link}