

To combine the best features of DWH (structured, manageable, high performance analytics) and Data Lake (scalability, handling heterogeneous data), the Data Lakehouse approach was developed. This architecture combines the flexibility of data lakes with the powerful processing and management tools typical of traditional warehouses, striking a balance between storage, analytics and machine learning. Data Lakehouse is a synthesis of data lakes and data warehouses, combining the flexibility and scalability of the former with the manageability and query optimization of the latter.
Data Lakehouse is an architectural approach that seeks to combine the flexibility and scalability of data lakes with the manageability and query performance of data warehouses (Fig. 8.1-9).
Key features of the Data Lakehouse include:
Open storage format: using open formats for data storage, such as Apache Parquet, provides efficiency and query optimization.
Read-only schema: in contrast to the traditional approach of a write-only schema in DWH, Lakehouse supports a read-only schema, which allows more flexibility in managing the data structure.
Flexible and scalable: supports storage and analysis of structured and unstructured data, providing high query performance through storage-level optimization.
Data Lakehouse offers a compromise solution that combines the benefits of both approaches, making it ideal for modern analytic workloads that require flexibility in data processing.

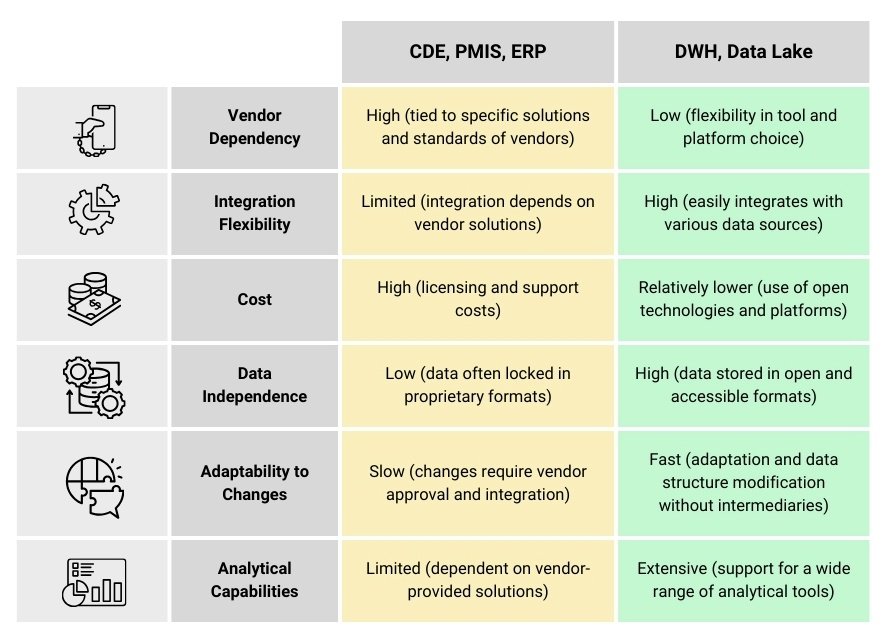
The idea of modern data warehouses seems simple: if all the data is in one place, it is easier to analyze it. However, in practice everything is not so smooth. Imagine that a company decides to completely abandon the usual accounting and management systems (ERP, PMIS, CAFM or others), replacing them with one huge data lake to which everyone has access. What will happen? Most likely chaos will ensue: data will be duplicated, contradictory, and critical information will be lost or corrupted. Even if the data lake is used only for analytics, without proper management, it will be severely compromised:
- Data is difficult to understand: in conventional systems, data has a clear structure, but in a lake, it is just a huge accumulation of files and tables. To find something, specialist has to Fig. out what each row and column is responsible for.
- Data can be inaccurate: if many versions of the same information are stored in one place, it is difficult to know which version is up to date. As a result, decisions are made based on outdated or erroneous data.
- It is difficult to prepare data for work: the data must not only be stored, but also presented in a convenient form – in the form of reports, graphs, tables. In traditional systems this is done automatically, but in data lakes it requires additional processing.
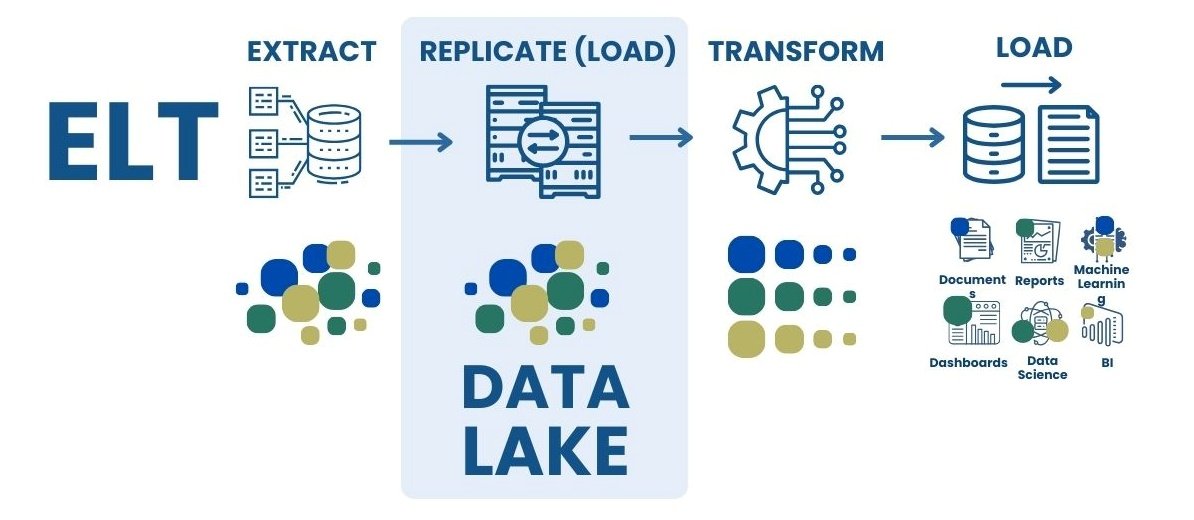
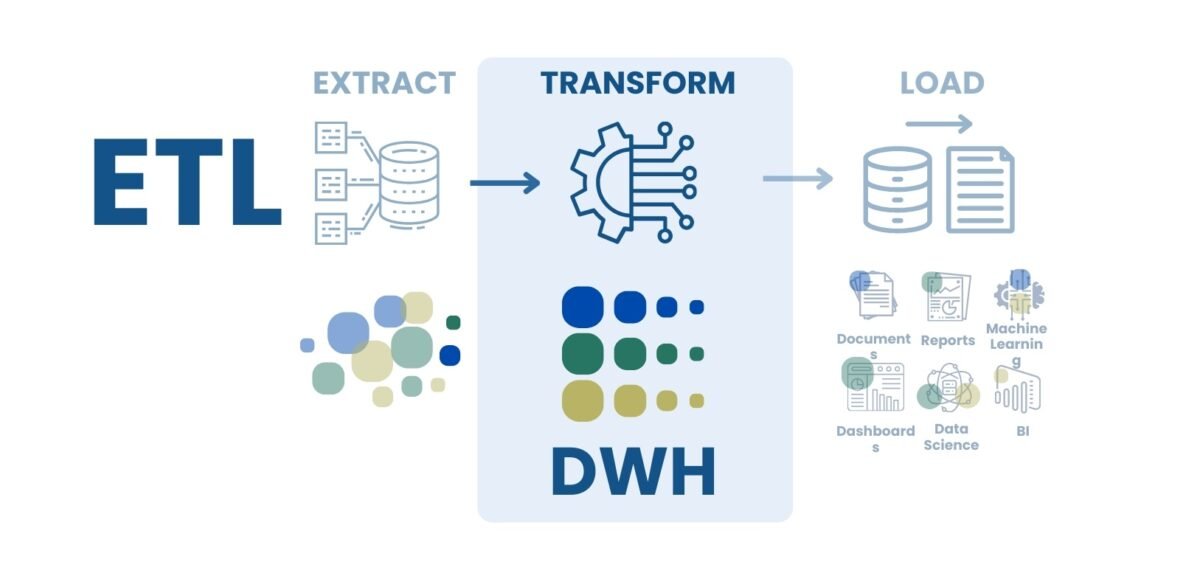
The bottom line is that each data warehousing concept has its own characteristics, processing approaches and business applications. Traditional databases focus on transactional operations, data warehouses (DWH) provide a structure for analytics, data lakes (Data Lake) store information in raw form, and hybrid warehouses (Data Lakehouse) combine the advantages of DWH and Data Lake (Fig. 8.1-10).

Choosing a storage architecture is a complex process, depending on business needs, information volume and analytics requirements. Each solution has its pros and cons: DWH provides structure, Data Lake provides flexibility, and Lakehouse provides a balance between the two. Organizations are rarely limited to a single data architecture.
Regardless of the chosen architecture, automated data management systems are significantly superior to manual methods. They minimize human errors, speed up information processing, and ensure transparency and traceability of data at all stages of business processes.
And while centralized data warehouses have already become an industry standard in many areas of the economy, the situation in construction remains fragmented. Data here is distributed across different platforms (CDE, PMIS, ERP, etc.), which makes it difficult to create a unified picture of what is happening and requires architectures capable of integrating these sources into a holistic, analytically usable digital environment.




















































{kind=link}
{kind=link}