


Mastery of vast sets of structured data represents the key to the world of Big Data - a realm where modern technology allows for the aggregation and analysis of vast amounts of information.
Big Data is an impressive amount of information that can include everything from freight elevator sensor data to construction site weather reports. When used correctly, Big Data becomes the basis for analytics, predictive modeling and decision making.
The application of Big Data in construction goes far beyond managing transaction records or weather forecasts. Big Data is transforming the construction industry in a myriad of ways:
- Investment Potential Analysis: Will use metrics from past projects to predict the profitability and payback of future projects.
- Predictive Maintenance: Uses historical data to predict equipment failures before they occur, reducing downtime.
- Supply Chain Optimization: Streamlines the delivery of materials and predicts supply chain disruptions.
- Energy Efficiency Analysis: Helps design buildings that consume less energy.
- Safety Monitoring: Uses wearables and sensors to monitor worker safety and environmental conditions on-site.
- Quality Control: Monitors construction processes in real-time to ensure compliance with standards and regulations.
- Workforce Management: Analyzes productivity and forecasts labor needs to optimize the allocation of human resources.
- Analyzing data from CAD (BIM): Enhances planning and management, providing insights to avoid design conflicts and maintenance issues.

IOT or data devices on a construction site can produce up to 1 Terabyte of data per day
In big data, a key skill is transforming data in various formats into a structured form, cleaning and preparing it for analytics, and being able to identify meaningful insights and formulate appropriate questions to visualise and analyse them.
Let's look at analytical and predictive examples on public datasets using big data tools.
In this chapter, we will and analyze a large dataset using data from various CAD (BIM) systems. A specialized automated web crawler, configured to automatically search and collect design files from websites offering free architectural models in Revit® and IFC formats, was used to create a large dataset. The crawlers successfully found and downloaded 4,596 IFC files and 6,471 Revit® files in a few days.
After collecting projects, in Revit® and IFC formats of different versions and after conversion using free reverse engineering SDKs, thousands of designs were collected into one big dataframe - the data form we talked about in the paragraph "DataFrame is a popular data structure".
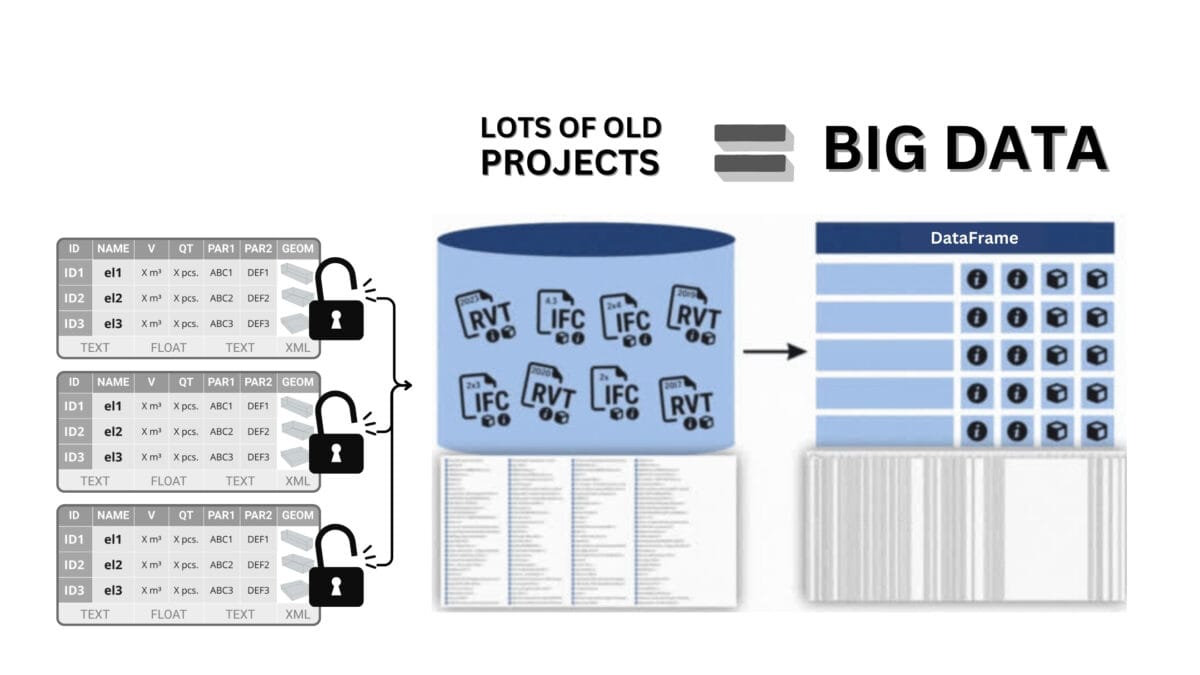
Having structured data enables it to be combined into large arrays, collecting thousands or millions of elements from different sources in a single table
The data from this large-scale collection contains the following details: the IFC files dataset contains approximately 4 million elements (rows) and 24,962 attributes (columns), and the Revit® files dataset of approximately 6 million elements (rows) contains 27,025 different attributes (columns).
These information sets span millions of elements, for each of which BoundingBox geometries were additionally derived (a rectangle that defines the boundaries of an object in the project) were additionally obtained and images of each element in PNG format and geometry in open XML - DAE (Collada) format were created.
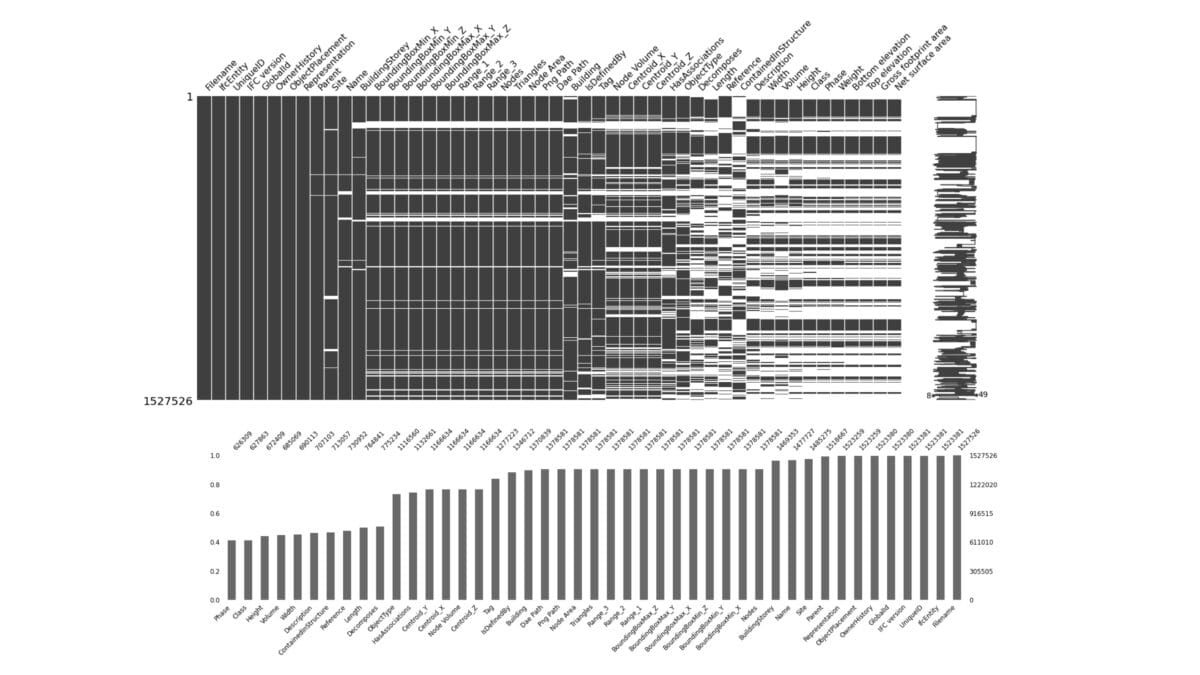
Dataset of 1.5 million elements and visualization of the occupancy of the first 100 attributes out of tens of thousands of all attributes of all projects
In this way we got all information on tens of millions of elements from 4,596 IFC projects and 6,471 Revit® projects where all properties of all elements and their geometry (BoundingBox) were translated into a structured form of just one table (DataFrame).
Such huge amounts of structured data open up limitless possibilities for analysis and decision-making. An example of analyzing this dataset is the "5000 projects IFC and Revit®" project, available on Kaggle. This ready-made Jupyter Notebook project includes not only code of the solutions and but also a clear visualization of the analytical results.
Using the Pandas library (which we discussed in detail in the chapter "Pandas: An Indispensable Tool in Data Analysis"), a general analysis of all elements from all projects was performed.
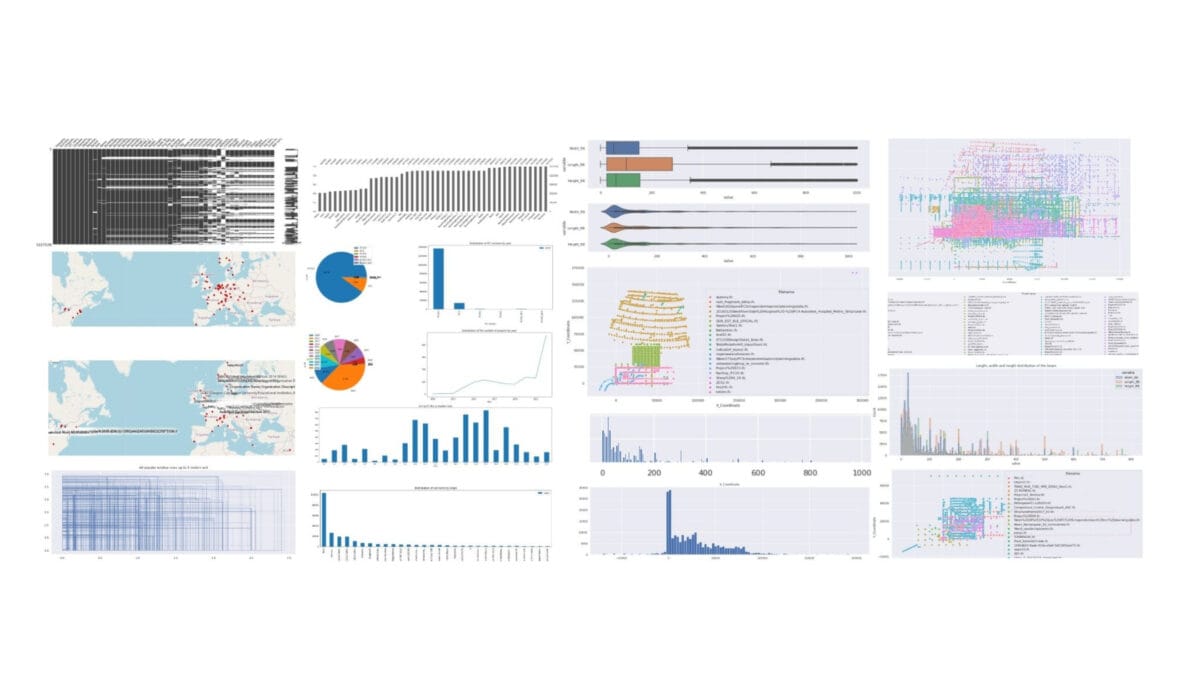
Analytics of tens of millions of elements from projects, including identification of project cities, analysis of file change times, and visualization of column geometries, windows from projects from around the world
For example, using project meta-information, it is possible to determine for which cities projects have been created by displaying this information on a map. From this dataset, as well, find out at what time of day, week, or month project files were saved or modified. Using BoundingBox geometry data, visualized all columns from all projects in one image in just a few seconds, and showed the dimensions of all windows from various projects from around the world in one image.
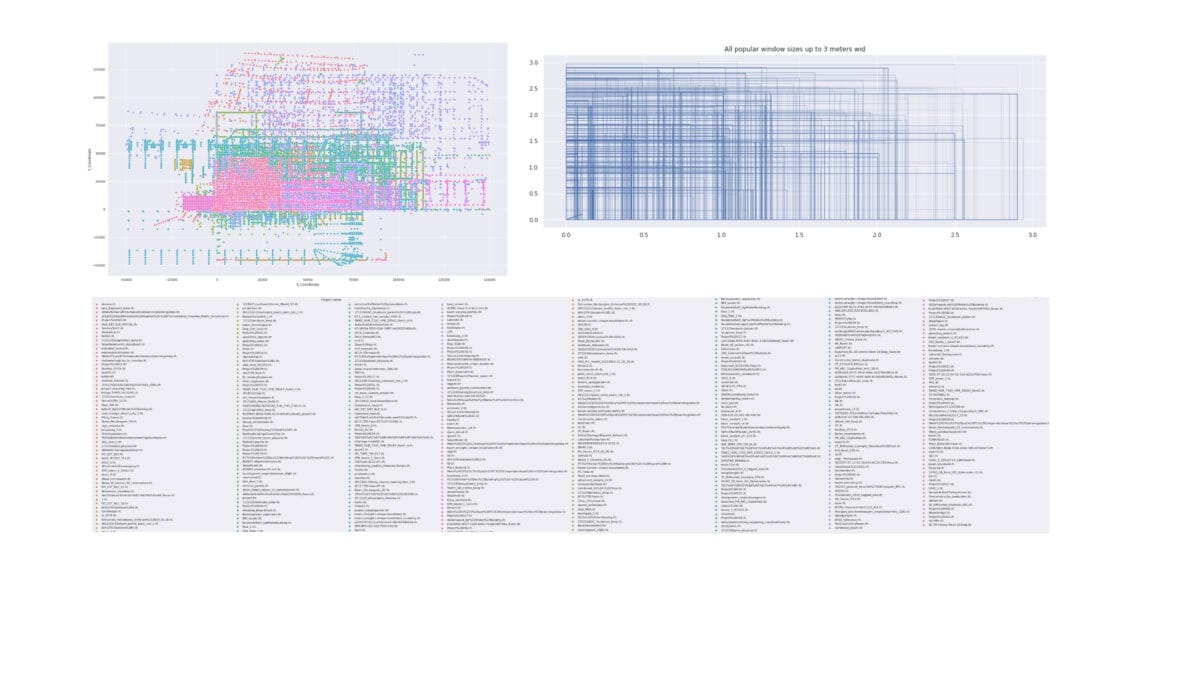
Visualization of geometric position of all columns to coordinates 0,0,0 and sizes of all windows up to 3 meters in all projects from the list at the bottom.
The Pipeline analytics code for this example and the dataset itself is available on the Kaggle website under the name "5000 projects IFC and Revit® | DataDrivenConstruction.io". This Pipeline together with the dataset can be copied and run in one of the popular IDEs: PyCharm, Visual Studio Code (VS Code), Jupyter Notebook, Spyder, Atom, Sublime Text, Eclipse with PyDev plugin, Thonny, Wing IDE, IntelliJ IDEA with Python plugin, JupyterLab or popular online tools Kaggle.com, Google Collab, Microsoft Azure Notebooks, Amazon SageMaker.
With this information analysis using data from past projects, professionals can effectively predict material and labour requirements and optimise design decisions before construction begins.
The analytics derived from the processing and exploration of massive amounts of structured data are crucial in the decision-making process in the construction industry.
But back to the realities of the construction industry: while self-driving cabs are already popping up in San Francisco, the companies working in the construction industry are still manual and often paper-based businesses where decisions are based more on intuition and experience than on data.
Recently, the construction sector in most countries has faced high central bank interest rates, cooling investor activity and falling margins to 1-2% of project costs. And with the introduction of new requirements to hand over CAD (BIM) models to clients or banks issuing construction loans, the opening up of volume data makes traditional speculation on volume and cost effectively unrealistic. All these financial difficulties, as well as the risk of bankruptcy and lack of liquidity, will push construction companies to incorporate automation, big data and analytics into their operations as the only tools to survive and improve efficiency in today's realities.
The availability of large amounts of open data and the realisation that predictive models can be created from it opens the door to the world of statistics, forecasting and machine learning.






















































