
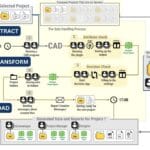

The first stage of the ETL process – Extract) – starts with writing code to collect data sets to be further checked and processed. To do this, we scan all the folders of the production server, collect documents of a certain format and content, and then convert them into a structured form. This process is discussed in detail in the chapters “Converting unstructured and textual data into structured form” and “Converting CAD data (BIM) into structured form” (Fig. 4.1-1 – Fig. 4.1-12).

As an illustrative example, we use the Extract data loading step and obtain a table of all CAD- (BIM-) projects (Fig. 7.2-4) uses reverse engineering-enabled converters(“Convertors,” 2024)for RVT and IFC formats to obtain structured tables from all projects and combine them into one large DataFrame table.

Pandas DataFrame can load data from a variety of sources, including CSV text files, Excel spreadsheets, JSON – and XML – files, big data storage formats such as Parquet and HDF5, and from MySQL, PostgreSQL, SQLite, Microsoft SQL Server, Oracle and other databases. In addition, Pandas supports loading data from APIs, web pages, cloud services and storage systems such as Google BigQuery, Amazon Redshift and Snowflake.
- To write code to connect and collect information from databases, send a similar text request to the LLM chat room (CHATGP, LlaMa, Mistral DeepSeek, Grok, Claude, QWEN or any other):
Please write an example of connecting to MySQL and converting data to ⏎
 |
The resulting code (Fig. 7.2-5, Fig. 7.2-6) can be run in one of the popular IDEs (integrated development environments) we mentioned above in offline mode: PyCharm, Visual Studio Code (VS Code), Jupyter Notebook, Spyder, Atom, Sublime Text, Eclipse with PyDev plugin, Thonny, Wing IDE, IntelliJ IDEA with Python plugin, JupyterLab or popular online tools: Kaggle.com, Google Collab, Microsoft Azure Notebooks, Amazon SageMaker.
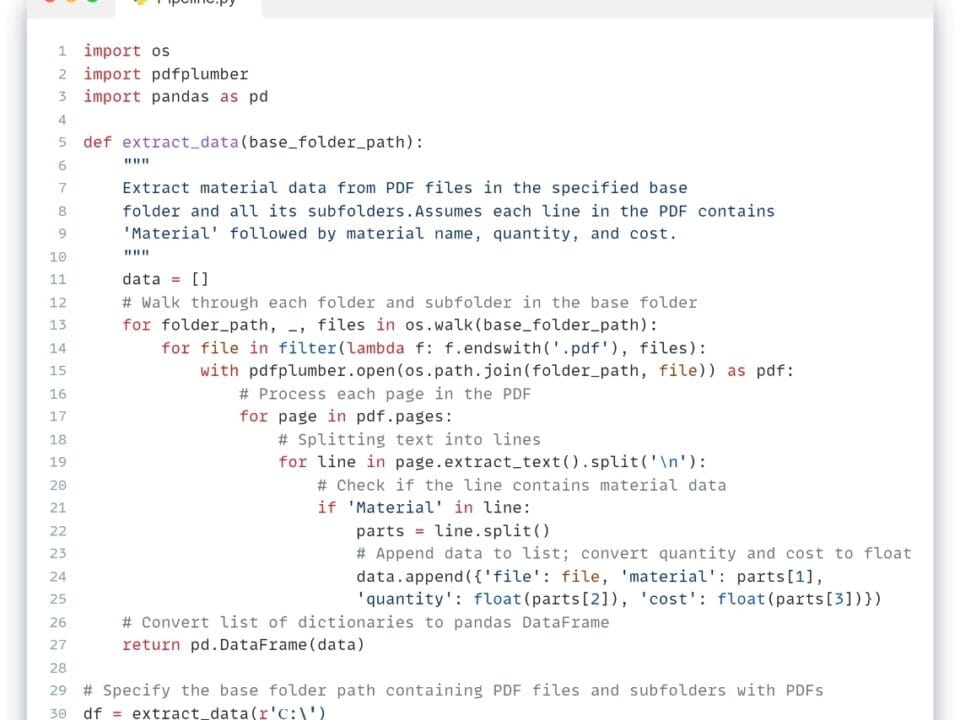
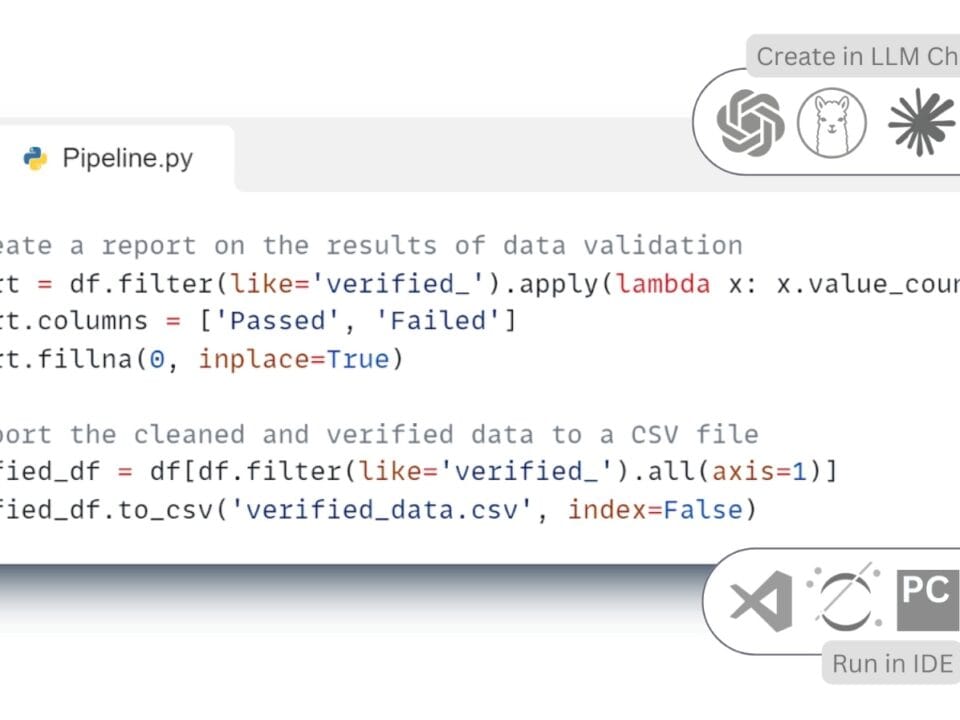
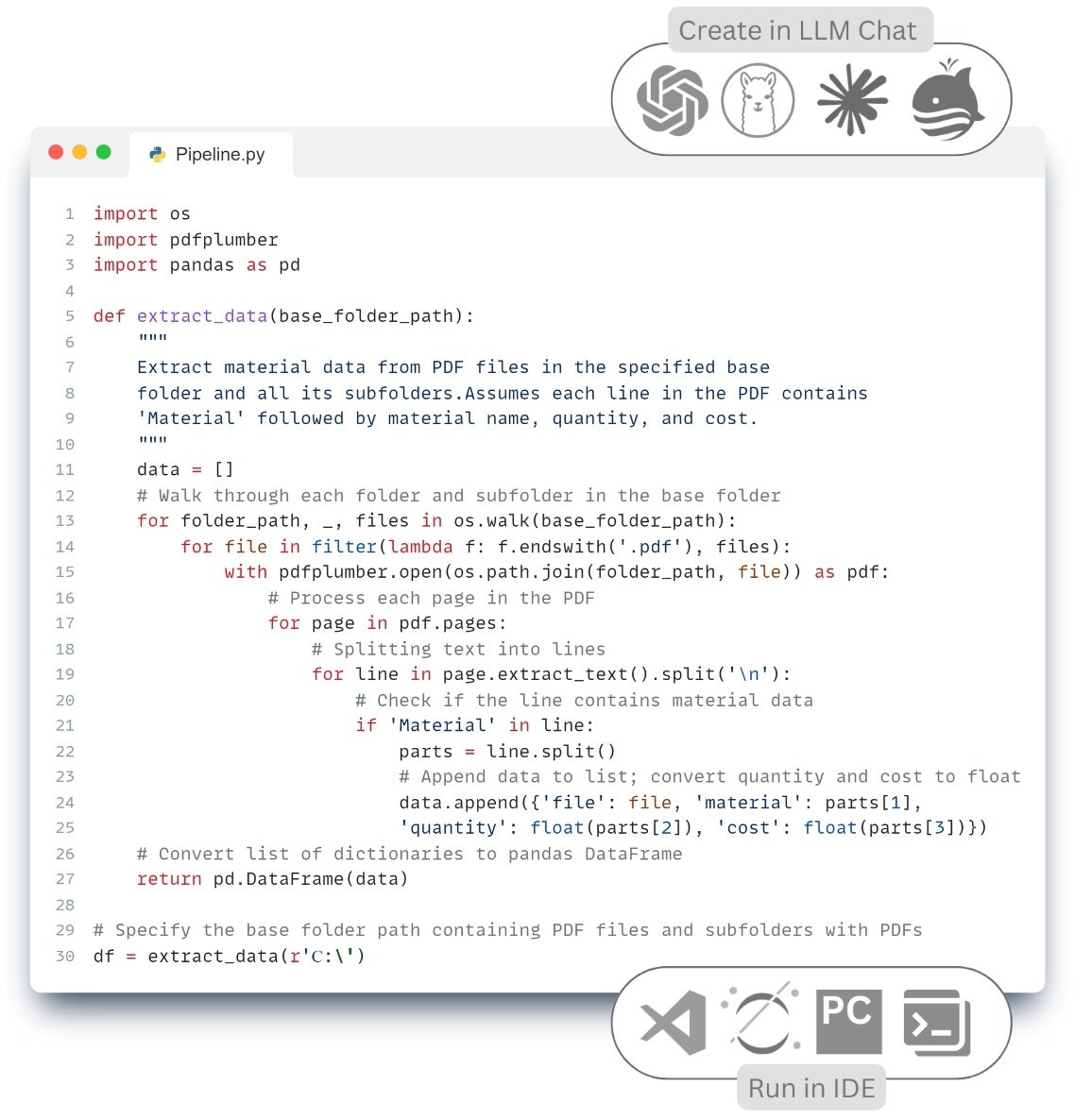
By loading the multiformat data into the variable “df” (Fig. 7.2-5 – row 25; Fig. 7.2-6 – row 8), we converted the data to the Pandas DataFrame format, one of the most popular structures for data processing, which is a two-dimensional table with rows and columns. We will talk more about other storage formats used in ETL -Pipelines such as Parquet, Apache ORC, JSON, Feather, HDF5, and modern data warehouses in the chapter “Data Storage and Management in the Construction Industry” (Fig. 8.1-2).
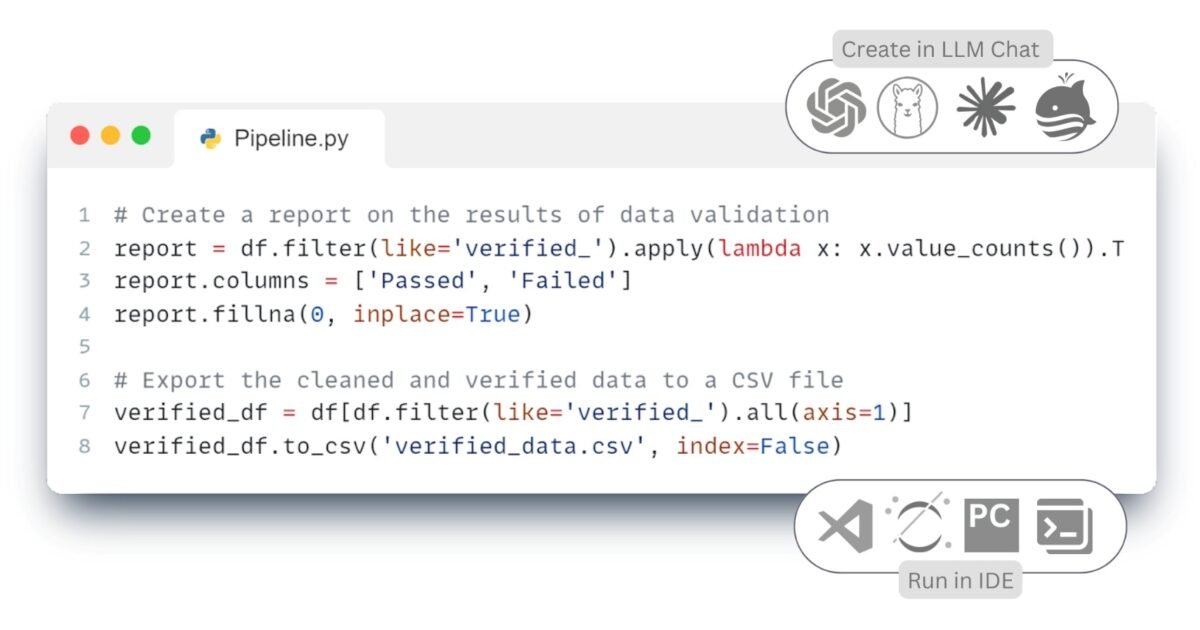
After the stage of data extraction and structuring (Extract), a single array of information is formed (Fig. 7.2-5, Fig. 7.2-6), ready for further processing. However, before loading this data into target systems or using it for analysis, it is necessary to ensure its quality, integrity and compliance with the specified requirements. It is at this stage that data transformation (Transform) is performed, a key step that ensures the reliability of subsequent conclusions and decisions.





















































{kind=link}
{kind=link}
{kind=link}